Индивидуальные APT репозитории для CPU
Интересный факт - все приложения, находящиеся в стандартных репозиториях Debian или Ubuntu, скомпилированы с опциями по-умолчанию. Это приводит к интересным последствиям. Например, программисты не используют SIMD инструкции и полагаются на компилятор. Компилятор не всегда может оптимизировать код под конкретный процессор. Из-за этого все супер-быстрые возможности процессоров и невероятные SIMD операции простаивают без дела.
Разработчики Debian объясняют эту особенность тем, что включение поддержки расширенных регистров не даёт существенного ускорения. И, зачастую, это верно. Разработчики не будут писать на ассемблере код, чтобы оптимизировать приложения для какого-то одного процессора. Да и не многим приложениям это нужно. А даже, если и написать более оптимизированный код, то непонятно как доставить его пользователю. Получается замкнутый круг: операционным системам невыгодно держать инфраструктуру бинарных пакетов для улучшения производительности на 5-10%. А разработчики не будут писать оптимизированный код, потому что нет инфраструктуры.
Тем не менее, есть отдельные библиотеки, которые оптимизированы специально для разных версий процессоров и по-максимуму используют их возможности. Например, volk позволяет предоставляет набор функций оптимизированный для цифровой обработки сигналов. Если процессор поддерживает оптимизированную реализацию и такая реализация написана, то volk выбирает её. Если нет, то подставляется реализация, которая написана на простом C. Получается, не нужно писать код под каждый тип процессора. Это хорошо, но остаётся другая проблема - дистрибьюция таких библиотек.
Эту-то проблему я и решил на прошлой неделе. Однако, прежде, чем переходить к решению, нужно понять “а как вообще работает дистрибьюция APT пакетов?”
APT репозитории
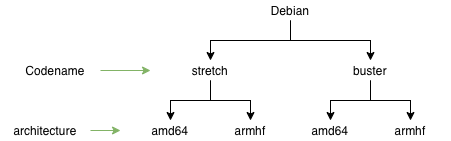
Я постараюсь описать схему репозиториев Debian, но это абсолютно так же работает и для Ubuntu. Итак, у каждого дистрибутива есть кодовое имя. Это кодовое имя даётся разным версиям операционной системы. В контексте компиляции это значит, что в разных версиях будут разные версии GCC и разные версии libc. Из чего зачастую следует, что пакет собранный в одной версии операционной системы, может не работать в другой. Иногда это не так, но в общем случае следует собирать пакет для каждой версии ОС.
У каждой версии ОС есть список архитектур, которые она поддерживает. На схеме выше я привёл только две: armhf и amd64. На самом деле, Debian поддерживает гораздо больше. Архитектура в контексте сборки приложения - это усреднённый тип процессора. Например, amd64 - это все 64-битные процессоры, а не только от AMD. То же самое и для armhf. armhf - это “обычный” 32-битный процессор на архитектуре ARM.
Для того, чтобы иметь бинарные приложения для каждого процессора, нужно пойти ещё дальше и добавить ещё один уровень.
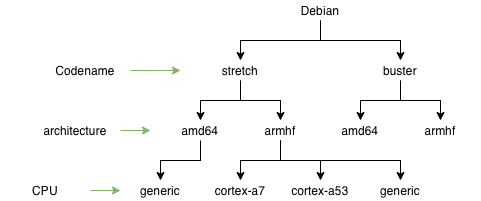
Можно иметь отдельные репозитории для различных версий ARM процессоров: cortex-a7, cortex-a53 и т.д. Также нужно иметь некоторую общую “generic” версию. Это на тот случай, если CPU не поддерживается. Каждый пакет должен быть собран под различные процессоры, а также с параметрами по-умолчанию для “generic” версии. На клиенте, подключение CPU-специфичного репозитория можно было бы сделать так (псевдокод):
deb http://s3.amazonaws.com/r2cloud/cpu-$(lscpu model or generic if not supported) $(lsb_release --codename --short) main
К сожалению, стандартный APT репозиторий не поддерживают такое детальное логическое разделение, поэтому его можно сделать на физическом уровне. Достаточно создать несколько разных репозиториев под разными URL. Выглядить это могло бы так:
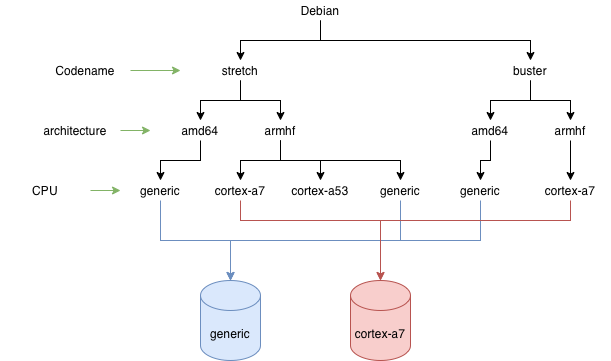
Получается несколько физических репозиториев, каждый из которых содержит:
- несколько версий ОС
- несколько архитектур
- только один тип процессора
Хорошая новость заключается в том, что типов процессоров не так много. Вдвойне хорошая новость заключается в том, что приложений, которые оптимизированы для нескольких процессоров не так много. Получается, что такие репозитории будут достаточно небольшими.
Флаги GCC
В предыдущей своей статье я описал опции компиляции для самого первого Raspberr pi, в котором стоит процессор ARM arm1176jzf-s. Однако, другие версии Raspberry pi содержат другие процессоры. Именно поэтому код, собранный под один процессор не запустится на другом:

Кстати, флаги компиляции для ARM процессоров нужно обязательно прописывать, потому что GCC по-умолчанию не включает поддержку расширенных регистров NEON. А вот для Intel x86_64 их включать необязательно, потому что они доступны по-умолчанию. Вот список тех флагов, которые нужно включать для различных версий Raspberry pi.
| Raspberry pi | Опции |
|---|---|
| Raspberry pi 1B | -mcpu=arm1176jzf-s -mfpu=vfp -mfloat-abi=hard |
| Raspberry pi 2 model B | -mcpu=cortex-a7 -mfpu=neon-vfpv4 -mfloat-abi=hard |
| Raspberry pi 3 | -mcpu=cortex-a53 -mfpu=neon-fp-armv8 -mfloat-abi=hard |
| Raspberry pi 4 | -mcpu=cortex-a72 -mfpu=neon-fp-armv8 -mfloat-abi=hard |
Реализация
После того, как стало ясно каким образом собрать и разложить бинарники по разным репозиториям, осталось всё это реализовать. Для разных APT репозиториев я создал несколько S3 bucket. Каждый из них содержит только специфичные для конкретного процессора бинарники. В результате в проекте r2cloud появилось два типа репозиториев:
- http://s3.amazonaws.com/r2cloud - в нём содержатся приложения не критичные к типу процессора. Там по-прежнему есть разделение на armhf и amd64.
- http://s3.amazonaws.com/r2cloud/cpu-* - в таких репозиториях содержатся приложения собранные под конкретные процессоры.
Для сборки приложений под конкретный тип процессора я написал небольшой bash скрипт. В нём определяется архитектура процессора (armhf или amd64):
CURRENT_ARCH=$(dpkg --print-architecture)
А после этого список поддерживаемых процессоров:
if [ "${CURRENT_ARCH}" = "armhf" ]; then
supported_cores="arm1176jzf-s cortex-a53 cortex-a7 cortex-a72 generic"
elif [ "${CURRENT_ARCH}" = "amd64" ]; then
supported_cores="generic"
else
echo "unknown arch: ${CURRENT_ARCH}"
exit 1
fi
Если приложение нужно собирать в зависимости от процессора (all), то запускается сборка для каждого из процессоров. Если нет (one), то приложение собирается для стандартного репозитория:
if [ "${CORE_BUILD}" = "all" ]; then
for i in ${supported_cores}; do
build_core $i
done
elif [ "${CORE_BUILD}" = "one" ]; then
build_core
else
echo "unknown core_build: ${CORE_BUILD}"
exit 1
fi
Результаты
В результате сборка стала занимать чуть больше времени. И для того, чтобы масштабироваться дальше, нужно уже что-то посерьёзнее обычного bash скрипта. Тем не менее для моих нужд этого вполне хватает и позволяет сильно упростить и ускорить приложения на Raspberry pi. Сама плата не очень быстрая, поэтому такая оптимизация крайне необходима.
Поскольку у меня теперь есть инфраструктура доставки приложений в зависимости от процессора, то в будущем можно заняться совсем уж экзотическими вещами вроде запуска кода на GPU. Тот же Raspberry pi содержит графическое ядро VideoCore IV, которое умеет перемножать матрицы и вектора очень быстро. А это крайне полезно для цифровой обработки сигналов.