DSP на Java
Java - язык программирования общего назначения. Общего назначения - значит можно писать почти любые программы. Вот я и попытался написать программу, которую обычно пишут на С или C++. Под катом я попытаюсь рассказать, как я декодировал спутниковые снимки с Метеор-М №2.

Предисловие
Когда я впервые заинтересовался декодированием спутниковых сигналов, то был, прямо говоря, удивлён. Сейчас софт для декодирования сигналов выглядит так же, как и библиотеки общего назначения лет 20 назад. Каждый пишет, что хочет, в каком хочет формате и совершенно не заботится о результатах. Яркий тому пример - декодирование сигнала с Метеор-М. Обычно алгоритм получения картинки выглядит следующим образом:
- Записать сигнал
- Запустить SDR# с определёнными плагинами и настройками и демодулировать сигнал. На выходе получается бинарный файл.
- Запустить LRPToffLineDecoder и на вход передать бинарный файл, полученный ранее.
- Из LRPToffLineDecoder сохранить картинку куда-нибудь.
Видимо, всех радиолюбителей такой подход устраивал, если за 9 лет существования спутника на орбите, ничего лучше не было придумано. Но для автоматического получения картинки такой подход не работает:
- Весь софт работает под Windows
- Нельзя запускать в headless режиме. Софт - это формочки с кнопочками.
- Невозможно получить обратную связь по приёму сигнала. Нет никаких метрик, по которым можно было бы оценить хорошо или плохо была принята картинка.
Из-за этого я забросил вэб формочки кровавого энтепрайза и начал долгое погружение в гремучий мир DSP. На полное декодирование сигнала у меня ушло 2 месяца свободного времени.
Разбор сигнала логически можно представить как две фазы:
- Демодуляция. Преобразование аудио-сигнала в информацию.
- Декодирование. Преобразование информации в понятный пользователю вид.
Демодуляция
Согласно официальной документации сигнал модулирован с помощью QPSK. Если вкратце, то для передачи двух бит информации используется одно положение фазы.
Итак, нужно демодулировать QPSK сигнал на Java. То ли никому это неинтересно, то ли Java медленная, но я не нашёл ни одной библиотеки, которые бы это делали. Поэтому я взял существующий проект демодуляции QPSK сигнала для GNURadio и начал переписывать блоки на Java.
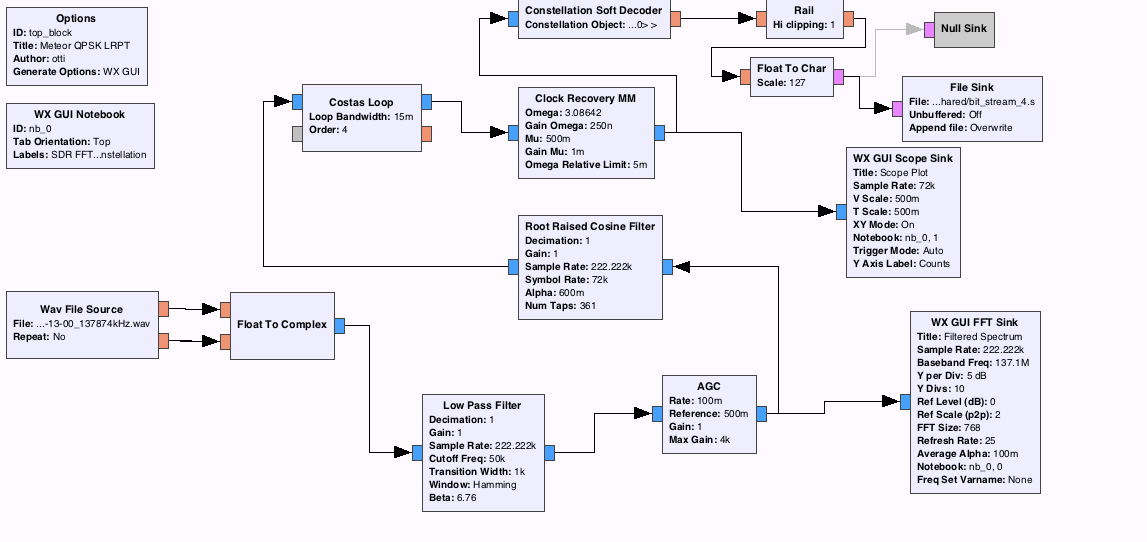
Блоки демодуляции
WavFile source и Float to Complex. Чтение из .wav файла IQ сигнала. Значения записаны в файле последовательно. Сначала реальная часть, потом мнимая, потом реальная и так далее. В GNURadio есть свои типы данных и каждый блок рассчитан для работы только с определёнными. Так как у нас QPSK модуляция, то нам нужно использовать комплексные числа. Здесь ничего сложного, так как в Java есть поддержка .wav файлов - AudioSystem.getAudioInputStream(inputStream).
Low Pass Filter. Это первый фильтр, который предназначен для фильтрации низких частот. Так как наш сигнал занимает 130Mhz, то нам надо отфильтровать лишние частоты.
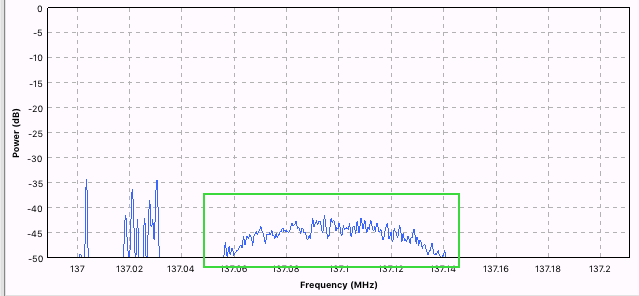
На картинке выше, частоты нашего сигнала обведены зелёным. Остальные частоты справа должны быть отфильтрованы. Это делается с помощью КИХ-фильтра. Для программиста это выглядит как:
- Взять последние N значений, текущее и положить в массив
- Перемножить получившийся массив с заранее заданным (вычисляется из ЛАФЧХ фильтра). По сути, перемножение одного вектора на другой.
- Все значения результирующего массива сложить.
- Это и будет результат.
AGC. Автоматическая регулировка усиления.
С точки зрения реализации - перемножение входного сигнала на некий уровень и вычисление следующего уровня в зависимости от текущего.
Root Raised Cosine Filter. Используется для уменьшения Intersymbol interference. Если вкратце, то при получении сигнала одни уровни переданного сигнала могут накладываться на последующие. Чтобы выделить максимальный уровень сигнала между символами, применяют этот фильтр. Работает так же как и Low Pass Filter, но использует другую ЛАФЧХ
Costas Loop - это алгоритм фазовой подстройки частоты. Для чего он нужен? Например, для того, чтобы корректировать доплеровское смещение частоты. Так как, мы точно знаем, что фаза у нас скачет по четырём уровням, то можно сравнивать значение двух разных фаз. Если оно отличается на дельту, то корректировать частоту. Это ярче всего видно на картинках внизу.
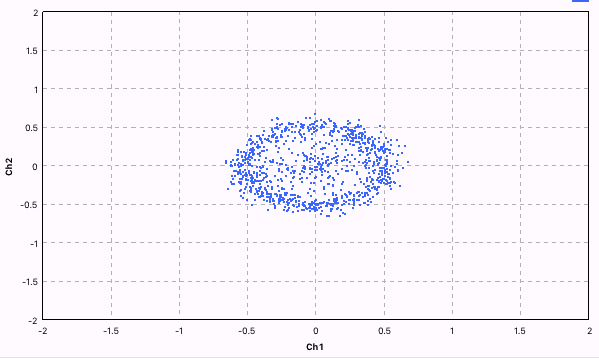
До коррекции частоты, у нас круг (почти). Это значит, что частота немного меняется каждый раз, и точки фазы не попадают в одно и то же место.
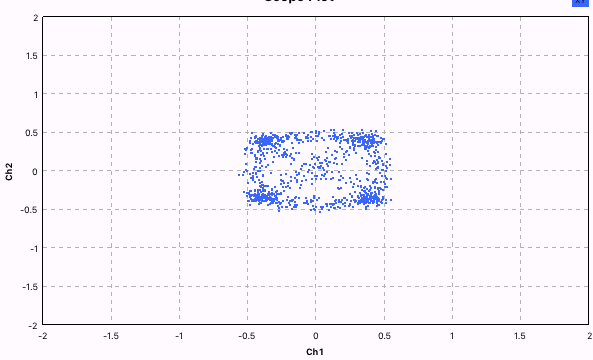
Здесь уже значительно лучше - видны 4 отчётливые точки фазы.
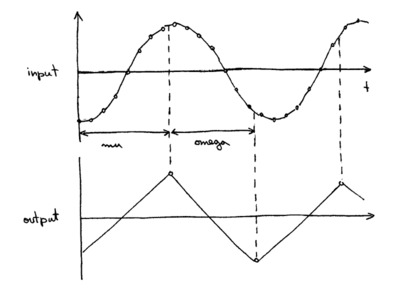
Clock recovery MM. Этот блок пытается восстановить шаг часов передатчика и отбрасывает все сэмплы, которые не относятся к изменению уровня. Примерная схема работы изображена ниже:
После того как все лишние сэмплы выкинуты, получается хорошее QPSK созвездие.
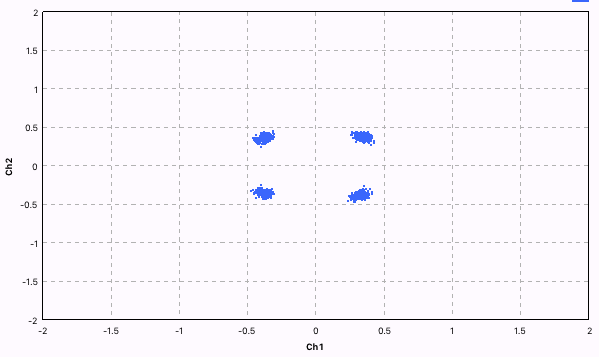
Constellation Soft Decoder. Этот блок преобразует координаты в вероятность битов. Тут надо остановиться поподробнее, так это очень важно в дальнейшем. Допустим все точки у которых координаты положительные будут отображаться в пару “00”.
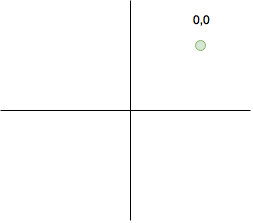
Теперь допустим, что мы получили значение в красной точке.
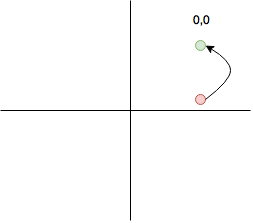
Если мы будем делать жёсткое решение, то координаты красной точки мы преобразуем в пару “00”. При этом мы потеряем информацию о том, что точка-то почти “01” (в нижним квадранте). А эта информация на самом деле может помочь в декодировании. Есть алгоритмы, которые дают лучшие результаты, если передать эту информацию. Поэтому вместо того, чтобы принимать жёсткое решение, надо посчитать вероятность 0 и вероятность 1. Например, 100% вероятность нахождения в правом верхнем квадранте будет 255,255. Использование мягких решений увеличивает поток данных в 8 раз, зато даёт более лучшие результаты при декодировании сигнала. Для того чтобы посчитать мягкое решение, необходимо рассчитать расстояние между текущей точкой и каждой из точек созвездия.
Rail, Float to char, File sink. Эти блоки немного преобразуют результаты и записывают их в файл. Для моего декодера записывать результаты в промежуточный файл не надо. Но в целях отладки было крайне полезно сначала демодулировать сигнал из Java, а затем посмотреть может ли LRPToffLineDecoder извлечь картинку.
Декодирование
Итак, у нас есть поток 0 и 1 из которого нужно получить картинку. Для начала необходимо открыть официальную документацию, где неплохо описана структура пакетов. Некоторые моменты там были опущены, поэтому я открыл еще более официальную документацию.
Декодирование состоит из следующих этапов:
- поиск в потоке бит синхромаркера. Каждый пакет начинается с него.
- после того как синхромаркер был найден, декодировать следующие 16384 бита алгоритмом Витерби
- результат подвергнуть скрэмблированию, после чего
- применить коды Рида Соломона и извлечь данные транспортного кадра
- из последовательности транспортных кадров извлечь последовательность парциальных пакетов. Для тех, кто изучал модель OSI вопросов быть не должно.
- из парциальных пакетов извлечь MCU формата JPEG
- декодировать пикселы JPEG, используя коды Хаффмана и Run-length coding
- правильно заполнить пикселами картинку с учётом пропущенных пакетов
- наложить 3 канала друг на друга с учётом пропущенных пакетов
Пожалуй я не буду здесь рассказывать про каждый из алгоритмов. Они сами по себе потянут на отдельную статью. Хочу лишь выложить результаты работы моей программы, официальной и на паскале.

К сожалению общая картина занимает 4500x2800px, поэтому я привожу сильно пожатую версию.
Оптимизации
А при чём тут Java? - скажут самые стойкие, кто смог дочитать до сюда.
Сейчас будет немного Java. Дело в том, что оптимизацию имеет смысл для корректно работающей программы. После каждого шага оптимизации можно запустить тесты и убедиться, что всё по-прежнему работает корректно.
Итак, я начну с декодирования. При запуске профайлера, ничего странного не обнаружилось:
- одно ядро работает на полную мощность
- самый горячий метод - это декодирование Витерби. Сложность этого алгоритма О(T*S), где T - это длина массива данных, S - пространство состояний. В нашем случае у нас 8 (бит) * 4 (00,01,10,11) = 32.
Помимо CPU, я запустил еще анализ аллокаций объектов. Оказывается, этот метод создаёт миллионы короткоживущих объектов. Они создают лишнюю нагрузку на GC и процессор. Посмотрим, можно ли это оптимизировать. Наивная реализация создаёт связный список для хранения решений каждого входящего бита:
LinkedList<long[]> decisions = new LinkedList<long[]>();
for (int i = 0; i < data.length; i += 2) {
long[] d = new long[2]; //decision
for (int b = 0; b < 32; b++) {
d[b / 16] = ...;
}
...
decisions.add(d);
}
Это можно попробовать развернуть в одномерный массив и обращаться к результатам хитро вычисляя индекс. Например, так:
long[] decisions = new long[data.length];
for (int i = 0; i < data.length; i += 2) {
decisions[i + b / 16] = ...;
}
В итоге на одно декодирование создаётся один объект - массив decisions. ViterbiSoft можно ещё дальше оптимизировать. Например, зная то, что размер массива всегда одинаковый, создать long[] decisions в конструкторе и переиспользовать.
Ещё одним проблемным местом оказался класс FixedLengthTagger. Этот класс содержит скользящее окно. Оно работает следующим образом:
- новый байт читается из источника
- записывается в конец окна
- если размер окна больше размера пакета, то удалить байт из начала окна
Наивная реализация использовала LinkedList
window.offerLast(curByte);
if (window.size() > packet_len) {
window.removeFirst();
}
На самом деле это очень накладная операция, так как на каждую операцию offerLast внутри LinkedList создаётся объект Node. Он будет содержать наш байт и иметь ссылки на следующий элемент списка и предыдущий. Однако, зная, что размер нашего окна фиксированный, его можно заменить на циклический массив:
window[windowIndex] = curByte;
windowIndex++;
if (windowIndex >= window.length) {
windowIndex = 0;
}
Для того чтобы правильно взять его содержимое надо скопировать данные до текущего указателя первыми и после текущего указателя последними. Как то так:
byte[] packet;
System.arraycopy(window, windowIndex, packet, 0, window.length - windowIndex);
System.arraycopy(window, 0, packet, window.length - windowIndex, windowIndex);
Эти две оптимизации позволили уменьшить время декодирования файла с 4 минут до 20 секунд. Для сравнения LRPToffLineDecoder делает это за 40 секунд.
Декодирование можно ещё немного оптимизировать, но в ущерб читаемости. Вместо этого можно попробовать ускорить демодуляцию.
Алгоритмы демодуляции на входе получают большой поток данных, а на выходе выдают сравнительно небольшой. Поэтому эти алгоритмы очень чувствительны к различным оптимизациям. При запуске профайлера, видно, что большая часть приходится именно на математические операции внутри блоков.

Тут мало что можно сделать: память не выделяется, безумных циклов нет. Единственное, что интересно проверить это компилирует ли Java JIT код в SIMD инструкции. Если вкратце, то это специальные инструкции процессора, которые работают с 128битными регистрами и обрабатывают их одной командой. Схематично это выглядит так:
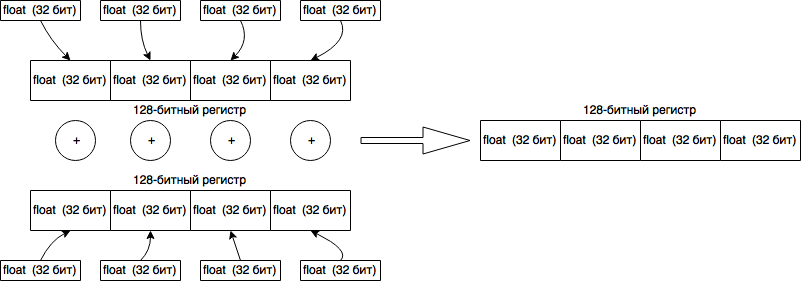
Как видно, такие инструкции идеально ложатся на КИХ-фильтры. GNURadio использует библиотеку VOLK, которая в зависимости от поддерживаемой архитектуры, может использовать SIMD инструкции. В Java скорей всего вызывать JNI обёртку будет значительно затратнее, чем выигрыш от использования таких инструкций. Одна надежда на JIT, который может оптимизировать перемножение одного массива на другой. Чтобы это проверить, необходимо запустить JVM с опцией “-XX:CompileCommand=print,*FIRFilter.filterComplex”. Она заставит JVM выводить ассемблерный код для метода filterComplex из класса FIRFilter.
Вот что у меня получилось при запуске с Oracle JDK 1.8.0_161 на MacBook Air:
0x0000000115994750: vmovss 0x10(%r10,%r11,4),%xmm1 0x0000000115994757: vmulss 0x10(%rcx,%r11,4),%xmm1,%xmm4 0x000000011599475e: vmulss 0x10(%r8,%r11,4),%xmm1,%xmm1 0x0000000115994765: vaddss %xmm2,%xmm4,%xmm3 0x0000000115994769: vaddss %xmm0,%xmm1,%xmm0 0x000000011599476d: movslq %r11d,%r9 0x0000000115994770: vmovss 0x1c(%r10,%r9,4),%xmm2 0x0000000115994777: vmulss 0x1c(%rcx,%r9,4),%xmm2,%xmm8 0x000000011599477e: vmulss 0x1c(%r8,%r9,4),%xmm2,%xmm1 0x0000000115994785: vmovss 0x14(%r10,%r9,4),%xmm4 0x000000011599478c: vmulss 0x14(%rcx,%r9,4),%xmm4,%xmm2 0x0000000115994793: vmulss 0x14(%r8,%r9,4),%xmm4,%xmm5 0x000000011599479a: vmovss 0x18(%r10,%r9,4),%xmm4 ;*faload ; - ru.r2cloud.jradio.blocks.FIRFilter::filterComplex@24 (line 26)
Судя по всему SIMD инструкции не используются.
Ещё одним интересным местом стало вычисление sincos. Блок Costasloop вычисляет значение синуса и косинуса для одного и того же угла (фазы) для каждого входящего значения. В CPU есть специальная команда - fsincos. Она вычисляет одновременно синус и косинус угла. Однако, в Java такой функции нет. Да и реализовывать её непонятно как: надо либо возвращать double[] (а это сильно ударит по GC), либо возвращать одно значение как результат работы функции, а другое через изменяемый параметр (double в функцию Java передаётся копированием, а Double опять же ударит по GC). Наивная же реализация выглядит так:
float sinImg = (float) Math.sin(-d_phase);
float cosReal = (float) Math.cos(-d_phase);
Можно попробовать вспомнить тригонометрию и заменить на:
float sinImg = (float) Math.sin(-d_phase);
float cosReal = (float) Math.sqrt(1 - sinImg * sinImg) + calculate sign;
Переход с Math.cos на Math.sqrt позволил сократить время демодуляции с 6 минут до 5 минут и 30 секунд. Тригонометрические операции можно ещё больше ускорить, если использовать таблицы поиска. Однако, я пока не готов исследовать зависимость результатов декодирования от точности таблиц. Может быть кто-нибудь поможет с этим?
Заключение
Поскольку я использовал одни и те же блоки для демодуляции сигнала, то можно сравнить время работы Java программы и GNURadio. Как и ожидалось, GNURadio быстрее: ~2 минуты против 5.5 минут. Да, Java почти в 2 раза медленнее. Но, если учесть, что файл записывался в течение 15 минут, то производительности Java вполне хватит, чтобы в реальном времени демодулировать сигнал.