Настройка проекта на Си
У меня есть небольшой проект на Си, который позволяет сделать приватный apt репозиторий в облачном хранилище Selectel - apt-transport-swift. Почему именно на Си? Во-первых, я думал, что знаю Си. Во-вторых, в моём представлении все системные утилиты для массового пользования должны быть написаны на низкоуровневом языке. Это значит, что для запуска приложения у меня должны быть минимальное количество зависимостей и минимальное потребление памяти. Ведь я не знаю на каком железе будет запущена моя программа. Однако, с Си есть некоторые проблемы - это очень старый язык, в котором есть много устаревших конструкций и подходов. Я потратил почти неделю на то, чтобы настроить всевозможные утилиты для улучшения качества проекта. Ниже, я хочу поделиться своими результатами.
Система контроля версий
Git. Использовать какую-либо другую систему контроля версий в 2019 году было бы крайне эксцентрично. Я выбрал github, так как там хранятся все мои проекты.
Сборка
cmake. Мне необходимо будет собирать тесты, считать code coverage и пр. Обычный make был бы слишком простым. Какие-то специальные сборочные системы, например Eclipse CDT, слишком привязаны к IDE и запускать их, например в launchpad, невозможно. С помощью cmake я мог бы собирать проект в Ubuntu и в MacOS.
Continuous integration
travis-ci. Прежде всего, он бесплатный и хорошо интегрирован с github. Я его использую в нескольких проектах, и он вполне подходит для моих нужд.
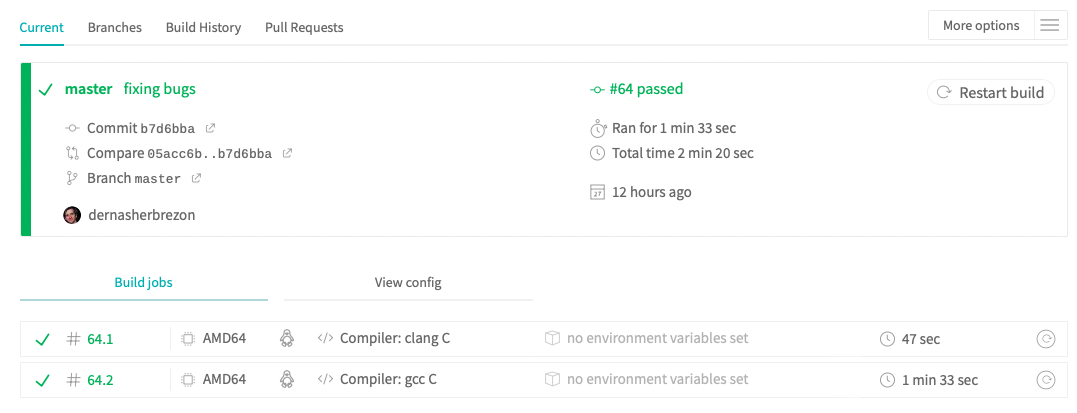
Continuous deployment
Launchpad. Не является классическим сервисом/приложением для continuous deployment. Тем не менее предоставляет в какой-то мере deployment. Например, он может автоматически собрать исходники под разные версии Ubuntu, под разные архитектуры и задеплоить в PPA. Сам по себе, Launchpad - это мир в себе. Я постараюсь написать отдельную статью, как собрать проект под него и какие особенности при этом могут возникнуть.
Тесты
libcheck. Для начала нужно отметить, что тесты для программы на Си существенно отличаются от тестов для таких языков как Java, Python, Ruby. Дело в том, что каждый тест нужно оборачивать в отдельную программу. Это нужно прежде всего, чтобы отловить memory access violation - наиболее частый тип ошибок. При таких ошибках программа обычно падает в coredump. Если тесты будут запускаться в рамках одного приложения, то ошибка в одном тесте будет валить все оставшиеся тесты. Это не очень хорошо, поэтому разработчики придумали делать fork тестов. Вообще с библиотеками для тестирования в мире Си всё достаточно сложно. Например, многие пытаются тестировать код embedded приложений, в которых очень важен размер программы и скорость, поэтому для каждого случая люди придумывают свою библиотеку тестирования. Иногда доходит до абсурда.
Отдельной головной болью является подключение этих библиотек. Дело в том, что в cmake модули и пакеты появились сравнительно недавно. И, видимо, чтобы не нарушить обратную совместимость, их поддержка выглядит очень специфической. Например, рекомендуемое подключение libcheck:
find_package(check <check_version if wanted> REQUIRED CONFIG)
target_link_libraries(myproj.test Check::check)
Со стороны выглядит компактно и просто. Однако, на практике тут прям совсем много проблем. Самая основная - эта конструкция работает только в libcheck >= 0.13.x. При этом в последней LTS Ubuntu libcheck версии 0.10.x. А это значит:
- нужно писать простыню FindCheck.cmake, в которой есть ошибка.
- не забыть обновить на более правильный способ подключения в следующей версии Ubuntu.
Тесты памяти
valgrind. Не секрет, что написать абсолютно корректную программу на Си или C++ практически нереально. Это прежде всего связано с моделью управления памяти. Очень просто выделить объект и забыть его удалить в нужный момент. В современных языках программирования обычно вводят garbage collector, который следит за выделением памяти и удаляет неиспользуемые объекты. Однако, в Си это необходимо делать самому и на помощь приходит вполне стандартный инструмент - valgrind. Единственное, над чем мне пришлось попотеть - это добавить его в continuous integration и сделать так, чтобы всё падало, если есть утечка памяти. Я запускаю его следующим образом:
set +e
EXIT_CODE=0
for file in test_*; do
[[ ${file} == *.dSYM ]] && continue
valgrind -v --error-exitcode=1 -q --tool=memcheck --leak-check=yes --show-reachable=yes ./${file}
CURRENT_EXIT_CODE=$?
if [ ${CURRENT_EXIT_CODE} != 0 ]; then
EXIT_CODE=${CURRENT_EXIT_CODE}
fi
done
exit ${EXIT_CODE}
В этом скрипте, для каждого теста выполняется анализ памяти, и, если статус не равен 0, скрипт возвращает ненулевой результат. Если travis получает ненулевой результат, то он завершает билд с ошибкой. Псевдокод выглядит как-то так:
script:
- set -e
- ./run_tests.sh
Code coverage
gcov. Многие думают, что считать покрытие тестами кода - это какой-то фетишизм педантов-максималистов. На самом деле, он прежде всего помогает найти неиспользуемый код, который можно удалить. И только во-вторую очередь позволяет понять насколько хорошо тесты написаны. Достигнуть 100% покрытия почти нереально, да и это зачастую не нужно. Многие сервисы, например sonarcloud, вполне это понимают и устанавливают границу в 80%. Судя по моему опыту, эта граница примерно соответствует тестам, которые проверяют успешное выполнение логики программы. Остальные 20% - это всевозможная обработка сложных граничных и многопоточных случаев.

Настройка gcov для связки travis и cmake выглядит нетривиально и многие в интернетах советуют переусложненные конфигурации. Мне же удалось сделать это проще.
Подключение debug информации:
if(CMAKE_BUILD_TYPE MATCHES Debug)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fprofile-arcs -ftest-coverage")
endif()
Вызов gcov для каждого объекта:
if(CMAKE_BUILD_TYPE MATCHES Debug)
add_custom_target("coverage")
add_custom_command(TARGET "coverage" COMMAND gcov ${CMAKE_BINARY_DIR}/CMakeFiles/swiftlib.dir/src/*.c.o)
endif()
При этом swiftlib содержит все объекты проекта за исключением main.c. Этот файл, в идеале, должен лишь содержать главный цикл или минимальный метод main:
int main(void) {
swift_start_main_loop();
}
Анализ кода
sonarcloud. Он поддерживает множество языков, в том числе Си, Java, Javascript, и я использую его во всех своих проектах. Удобно и бесплатно.
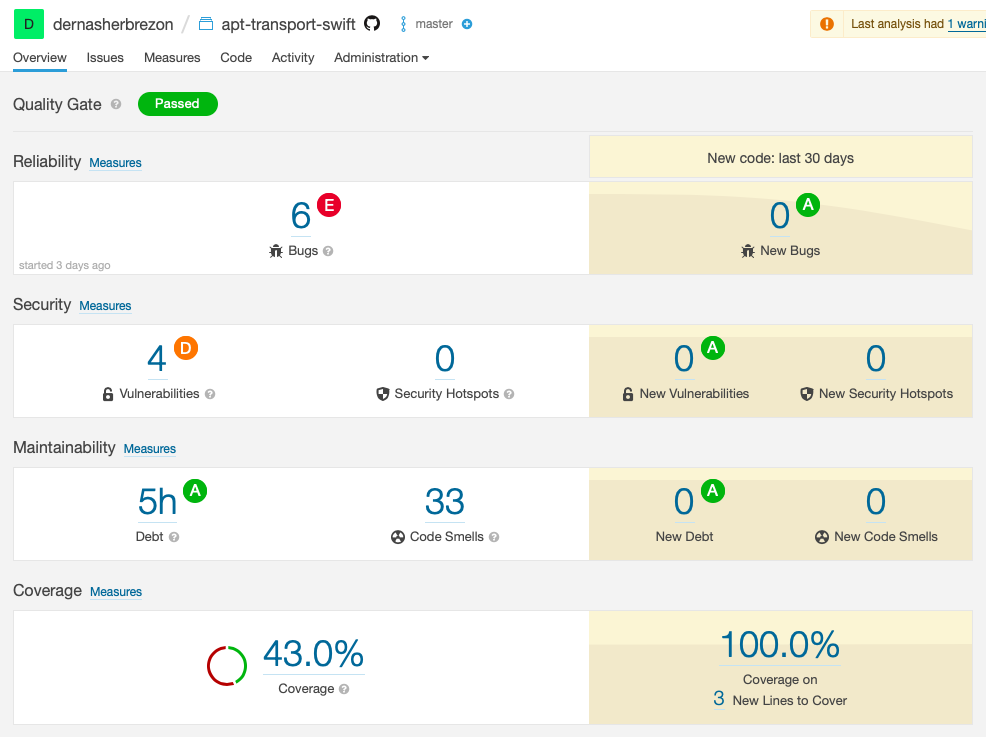
Выводы.
Мир Си странен и многообразен. Почти все инструменты, которые просто и быстро подключаются в современных языках программирования, здесь требуют доработки напильником. Однако, если есть желание разобраться с экосистемой, то всё возможно. После того как я всё настроил, стало хорошо видно, где стоит поработать. Например, я думал, что покрытие тестами в моём проекте примерно 60%. Однако, в реальности оно оказалось где-то 40%. Статический анализатор sonarcloud нашёл много серьёзных багов, связанных с памятью. Уже сейчас можно сказать, что время, потраченное на настройку, окупилось и принесло пользу.