Оптимизация SIMD кода
Остапа понесло.
“12 стульев”
Почувствовав прилив сил и некоторую уверенность после оптимизации программ на Си, я решил погрузиться ещё глубже. И поводом для этого стало странное поведение функции volk_8i_s32f_convert_32f под RaspberryPI.
В предыдущей статье я смог с помощью этой функции существенно ускорить работу своей программы sdr-server. На скриншоте ниже видно, что конкретная реализация этой функции под MacOS была volk_8i_s32f_convert_32f_u_sse4_1.
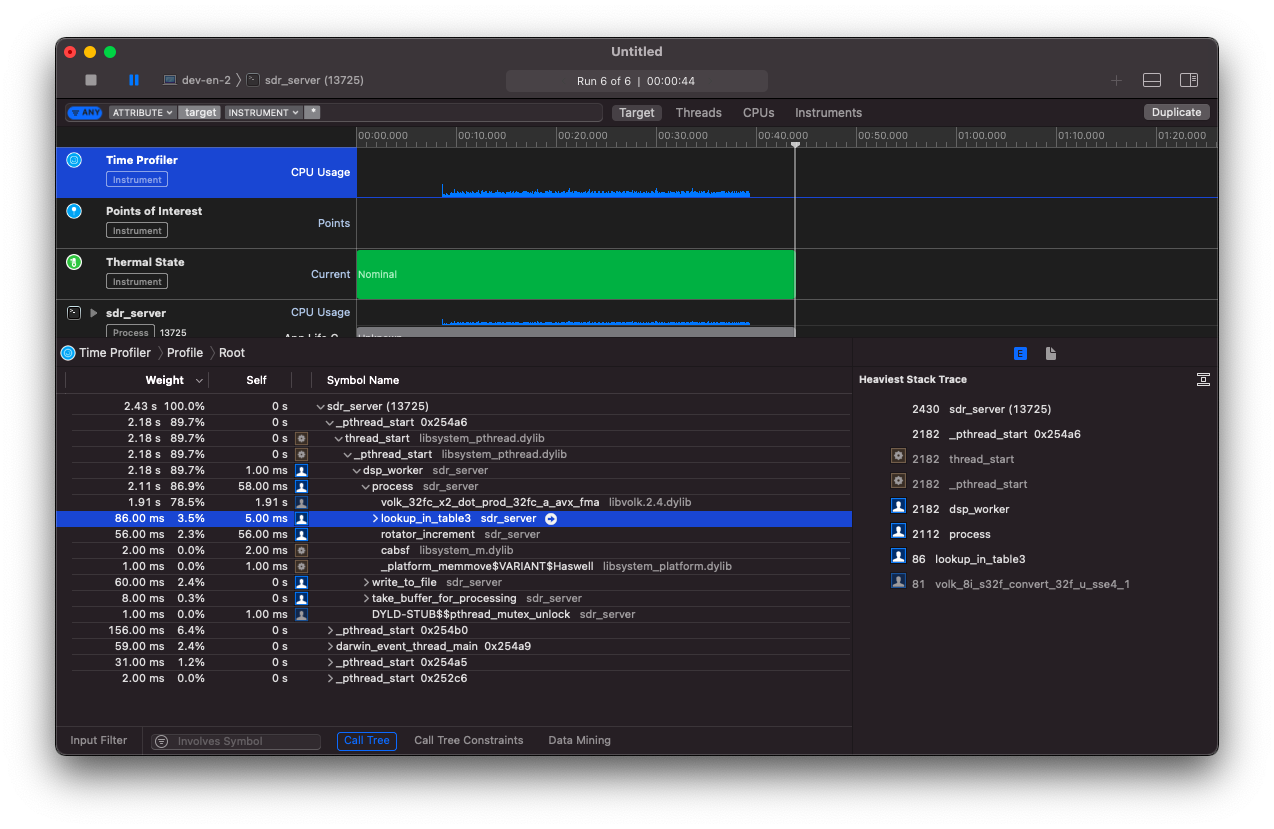
Это значит, что все метод реализован с помощью инструкций и регистров SSE4. Однако, запуская этот же код на RaspberryPI, я не заметил существенной разницы по сравнению с обычным циклом.
#: volk_profile -R volk_8i_s32f_convert_32f -n
RUN_VOLK_TESTS: volk_8i_s32f_convert_32f(131071,1987)
generic completed in 446.774 ms
neon completed in 434.753 ms
a_generic completed in 416.605 ms
Best aligned arch: a_generic
Best unaligned arch: neon
Warning: this was a dry-run. Config not generated
Разница между generic реализаций и специальной реализацией под ARM процессор (neon) несущественна. Это навело меня на мысли. Почему расширенные регистры в Intel работают быстрее, чем похожие регистры в ARM? Я не смог заглянуть внутрь реализации обоих процессоров, чтобы сравнить. Зато я решил открыть исходный код Volk и почитать.
Интристики
Первый же метод в функции пришлось гуглить. Оказывается код написан с использованием интристиков. Поэтому прежде, чем читать код, мне пришлось разобраться, что же это такое.
На самом деле, всё достаточно просто. Интристики - это некоторый промежуточный слой между ассемблером и языком Си. Они оборачивают инструкции ассемблера в функции на Си, чтобы можно было удобнее их читать. Иногда они могут подготавливать регистры ассемблера для вызова операции. Можно написать код на ассемблере и подключить его в программу на Си, но удобнее написать с помощью интристиков. А компилятор уже преобразует их в ассемблерные инструкции.
Для примера можно взять функцию vld1q_s8.
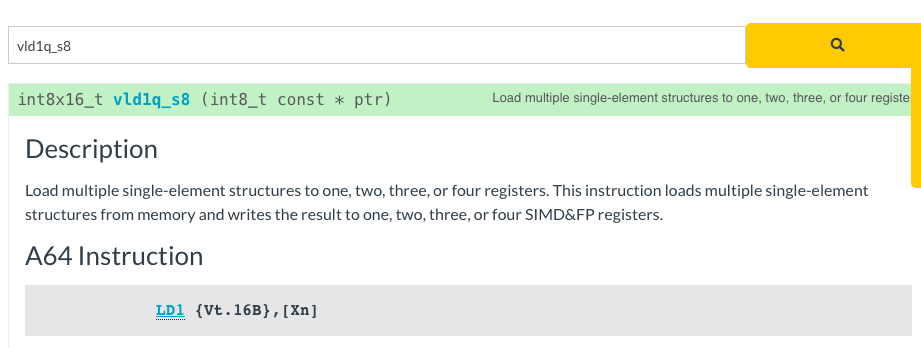
Эта функция загружает в регистр данные из памяти:
int8_t *inputVectorPtr;
int8x16_t inputVal = vld1q_s8(inputVectorPtr);
После этого можно выполнять необходимые SIMD инструкции над этими данными. При этом компилятор сам выбирает в какой именно регистр будут загружаться данные. Ассемблерный код выглядел бы так:
VLD1.16 {d0,d1}, [r0]
Оптимизация
Итак, теперь более-менее понятно, что такое интристики. Пришло время расчехлить теоретические знания, полученные более 15 лет назад, и попытаться разобраться, что происходит в методе.
А там почему-то используются структуры размерности 2 (int8x8x2_t) вместо обычных векторов. Мне показалось это странным.
int8x8x2_t inputVal;
float32x4x2_t outputFloat;
int16x8_t tmp;
unsigned int number = 0;
const unsigned int sixteenthPoints = num_points / 16;
for (; number < sixteenthPoints; number++) {
__VOLK_PREFETCH(inputVectorPtr + 16);
inputVal = vld2_s8(inputVectorPtr);
inputVal = vzip_s8(inputVal.val[0], inputVal.val[1]);
inputVectorPtr += 16;
...
Оригинальный код выглядит очень громоздким и профессионально написанным. Я же решил попробовать написать свой первый код с помощью интристиков и не слишком рассчитывал улучшить производительность. Вместо использования структур, я написал код с использованием обычных векторов int8x16_t.
int8x16_t inputVal;
int16x8_t lower;
int16x8_t higher;
float32x4_t outputFloat;
unsigned int number = 0;
const unsigned int sixteenthPoints = num_points / 16;
for (; number < sixteenthPoints; number++) {
inputVal = vld1q_s8(inputVectorPtr);
inputVectorPtr += 16;
...
Получилось значительно прямее и проще. Однако, не факт, что быстрее. Единственным способом проверить - это запустить код.
#: volk_profile -R volk_8i_s32f_convert_32f -n
RUN_VOLK_TESTS: volk_8i_s32f_convert_32f(131071,1987)
generic completed in 401.395 ms
neon completed in 324.097 ms
a_generic completed in 377.772 ms
Best aligned arch: neon
Best unaligned arch: neon
Warning: this was a dry-run. Config not generated
Какого же было моё удивление, когда я увидел 20% прирост производительности! Я перепроверил код ещё несколько раз, и всякий раз моя реализация оказывалась быстрее.

У меня нет достаточно знаний, чтобы точно сказать, почему мой код оказался быстрее. Тем не менее я выдвинул несколько теорий:
- gcc не смог оптимизировать слишком сложный код в оригинальном методе
- оригинальный код работал с N-мерными структурами, которые не подходят для таких простых операций
- оригинальный код был написан и оттестирован на armv8 (arm64), а не armv7 (RaspberryPI 3+)
В любом случае я создал pull request в оригинальный репозиторий и отправил его на ревью.
Результаты
Пожинать плоды моих усилий придётся нескоро. Для начала мой pull request должен быть проверен. Потом он должен попасть в master, и только потом, через какое-то время, он попадёт в релизную версию. Но вместо того, чтобы сидеть и ждать, я готов исследовать новые горизонты:
- попробовать сравнить libvolk и openmax. Возможно, в openmax уже реализован этот метод.
- попробовать собрать свою версию libvolk и подключить её в проект с помощью conan.io. Тогда не придётся ждать официального релиза.
В любом случае sdr-server есть куда улучшать.