Оптимизация OpenCL на RaspberryPI
Это третья статья в цикле про мои похождения в области распределённых вычислений. Первая статья была про то, зачем вообще нужен OpenCL и распределённые вычисления. Вторая статья про то, как настроить OpenCL для Raspberrypi, чем отличаются различные режимы работы и драйвера. Эта статья будет про оптимизацию OpenCL кода. Самое важное, что нужно понять: сможет ли GPU заменить или хотя бы приблизиться по производительности к CPU при выполнении Frequency Xlating FIR фильтра.
Измерения
Прежде, чем оптимизировать что-то, необходимо научиться измерять. А измерять скорость работы программы можно по-разному. Я пошёл самой простой дорогой:
int total_executions = 1000;
clock_t begin = clock();
for (int i = 0; i < total_executions; i++) {
fir_filter_naive_process(input, input_len, &output, &output_len, filter);
}
clock_t end = clock();
double time_spent = (double) (end - begin) / CLOCKS_PER_SEC;
printf("average time: %f\n", time_spent / total_executions);
Вызвать критичный участок кода N раз, замерить общее время выполнения, поделить на количество вызовов, получить среднее время выполнения. Этого вполне достаточно, чтобы сравнивать скорость работы между разными реализациями. В дальнейшем измерения нужно будет немного усложнить, но для начала этого вполне хватит.
Я запустил тест наивной реализации и получил следующую цифру:
average time: 0.050191
Это будет отправной точкой всех дальнейших оптимизаций.
Оптимизация OpenCL
Итак, самое сочное. Как оптимизировать OpenCL код? Я не имел ни малейшего понятия. Именно поэтому пришлось обратиться к Google, который выдал мне отличнейший гайд от TexasInstruments. Код, который там используется совсем не применим к нашей задаче, но идеи вполне можно попробовать.
Использование 1 work-item для 1 work-group
Первым же советом Texas Instruments было забыть все эти разбиения на work-item и work-group и сделать по-простому: 1 work-item для 1 work-group. По сути они советуют в каждом QPU выполнять только один work-item. Но этот work-item может считать не одно значение, а сразу несколько. В этом есть смысл, так как входящие данные будут строго локализованы для каждого ядра, а значит и cache hit будет значительно выше. Для фильтра это так же имеет смысл, так как каждый следующий результат использует почти те же самые входящие данные, что и предыдущий.
Код kernel будет выглядеть следующим образом:
for (unsigned int i = 0; i < output_len; i++) {
int output_offset = (get_global_id(0) * output_len + i) * 2;
int input_offset = output_offset * decimation;
float real0 = 0.0f;
float imag0 = 0.0f;
for (unsigned int j = 0; j < taps_len; j++) {
real0 += (input[input_offset + 2 * j] * taps[2 * j]) - (input[input_offset + 2 * j + 1] * taps[2 * j + 1]);
imag0 += (input[input_offset + 2 * j] * taps[2 * j + 1]) + (input[input_offset + 2 * j + 1] * taps[2 * j]);
}
output[output_offset] = real0;
output[output_offset + 1] = imag0;
}
Здесь видно, что каждый kernel будет считать output_len результатов. Тест производительности показал:
average time: 0.050315
И… Скорость почти не поменялась. Как же так? Чтобы понять, как именно отработал kernel, нужно больше метрик. К счастью, VC4CL позволяет выводить внутренние метрики GPU. Для этого нужно выставить переменную VC4CL_DEBUG.
sudo VC4CL_DEBUG=perf ./perf_fir_filter_naive
[VC4CL](VC4CL Queue Han): Performance counters for kernel execution: fir_filter_process
[VC4CL](VC4CL Queue Han): Elapsed time: 49195us
[VC4CL](VC4CL Queue Han): Clock speed: 0
[VC4CL](VC4CL Queue Han): Instruction count: 373
[VC4CL](VC4CL Queue Han): Explicit uniform count: 5
[VC4CL](VC4CL Queue Han): QPUs used: 12
[VC4CL](VC4CL Queue Han): Kernel repetition count: 17
[VC4CL](VC4CL Queue Han): Execution cycles: 117059316
[VC4CL](VC4CL Queue Han): Idle cycles: 3367764868
[VC4CL](VC4CL Queue Han): Instruction cache lookups: 29264829
[VC4CL](VC4CL Queue Han): Instruction cache misses: 390
[VC4CL](VC4CL Queue Han): L2 cache hits: 20723
[VC4CL](VC4CL Queue Han): L2 cache misses: 11539
[VC4CL](VC4CL Queue Han): TMU cache misses: 31824
[VC4CL](VC4CL Queue Han): TMU stall cycles: 59361392
[VC4CL](VC4CL Queue Han): TMU words loaded: 31713024
[VC4CL](VC4CL Queue Han): Uniform cache lookups: 2880
[VC4CL](VC4CL Queue Han): Uniform cache misses: 48
[VC4CL](VC4CL Queue Han): VPM DMA read stall cycles: 0
[VC4CL](VC4CL Queue Han): VPM DMA write stall cycles: 0
И для улучшенной версии:
sudo VC4CL_DEBUG=perf ./perf_fir_filter
[VC4CL](VC4CL Queue Han): Performance counters for kernel execution: fir_filter_process
[VC4CL](VC4CL Queue Han): Elapsed time: 49248us
[VC4CL](VC4CL Queue Han): Clock speed: 0
[VC4CL](VC4CL Queue Han): Instruction count: 432
[VC4CL](VC4CL Queue Han): Explicit uniform count: 6
[VC4CL](VC4CL Queue Han): QPUs used: 12
[VC4CL](VC4CL Queue Han): Kernel repetition count: 1
[VC4CL](VC4CL Queue Han): Execution cycles: 113019828
[VC4CL](VC4CL Queue Han): Idle cycles: 1836058716
[VC4CL](VC4CL Queue Han): Instruction cache lookups: 28254957
[VC4CL](VC4CL Queue Han): Instruction cache misses: 234
[VC4CL](VC4CL Queue Han): L2 cache hits: 10484
[VC4CL](VC4CL Queue Han): L2 cache misses: 67396
[VC4CL](VC4CL Queue Han): TMU cache misses: 77622
[VC4CL](VC4CL Queue Han): TMU stall cycles: 63784900
[VC4CL](VC4CL Queue Han): TMU words loaded: 31713024
[VC4CL](VC4CL Queue Han): Uniform cache lookups: 203
[VC4CL](VC4CL Queue Han): Uniform cache misses: 24
[VC4CL](VC4CL Queue Han): VPM DMA read stall cycles: 0
[VC4CL](VC4CL Queue Han): VPM DMA write stall cycles: 0
И, судя по метрикам, кэш наивной реализации гораздо более эффективен! L2 cache hits в 2 раза больше! Правда, на общий результат это не сильно повлияло.
Расширенные типы
Хорошо, а что насчёт расширенных типов? В OpenCL есть поддержка float8 и float16. Правда, я не совсем уверен, сможет ли VC4C правильно скомпилировать такой код. И даже если сможет, то будет ли он быстрее? В Videocore IV нет 256-битных SIMD регистров, поэтому одновременное умножение 8 разных float вряд ли возможно. С другой стороны в каждом QPU есть потоки и можно выполнять две операции параллельно. Единственный способ это проверить - написать и запустить код. В OpenCL есть забавный синтаксис для SIMD операций: можно обратится к чётным и нечётным элементам вектора. Перемножение комплексных чисел можно записать вот так:
__global float8 *in = (__global float8*)(input + input_offset);
__global float8 *tap = (__global float8*)taps;
float4 real0 = (float4)(0.0f, 0.0f, 0.0f, 0.0f);
float4 imag0 = (float4)(0.0f, 0.0f, 0.0f, 0.0f);
for (unsigned int j = 0; j < taps_len / 4; j++) {
real0 += in->even * tap->even - in->odd * tap->odd;
imag0 += in->even * tap->odd + in->odd * tap->even;
in++;
tap++;
}
output[output_offset] = real0.s0 + real0.s1 + real0.s2 + real0.s3;
output[output_offset + 1] = imag0.s0 + imag0.s1 + imag0.s2 + imag0.s3;
Правда, с этим кодом небольшая беда: он работает чуть хуже, чем портянка кода ниже: 0.017572 против 0.017017.
__global float8 *in = (__global float8*)(input + input_offset);
__global float8 *tap = (__global float8*)taps;
float real0 = 0.0f;
float imag0 = 0.0f;
float real1 = 0.0f;
float imag1 = 0.0f;
float real2 = 0.0f;
float imag2 = 0.0f;
float real3 = 0.0f;
float imag3 = 0.0f;
// taps_len guaranteed divided by 4
for (unsigned int j = 0; j < taps_len / 4; j++) {
real0 += (in->s0 * tap->s0) - (in->s1 * tap->s1);
imag0 += (in->s0 * tap->s1) + (in->s1 * tap->s0);
real1 += (in->s2 * tap->s2) - (in->s3 * tap->s3);
imag1 += (in->s2 * tap->s3) + (in->s3 * tap->s2);
real2 += (in->s4 * tap->s4) - (in->s5 * tap->s5);
imag2 += (in->s4 * tap->s5) + (in->s5 * tap->s4);
real3 += (in->s6 * tap->s6) - (in->s7 * tap->s7);
imag3 += (in->s6 * tap->s7) + (in->s7 * tap->s6);
in++;
tap++;
}
Что же тут происходит?
- Все данные преобразовываются к типу float 8.
- Вместо двух аккумуляторов
float realиfloat imagиспользуется 8. Не уверен, что это хорошая идея, так как в VideoCore IV есть только 4 регистра аккумулятора. Но с другой стороны, я не контролирую ассемблерный код, поэтому сложно сказать, как это будет скомпилировано. - Из-за того, что используется 8 аккумуляторов, точность вычислений повысится! См. попарное суммирование.
- Одновременно делается 4 перемножения комплексных чисел. Это значит, что taps_len должен быть кратен 4. Пришлось менять код вызывающей программы и создавать массив размером кратным 4.
Итак, 0.017017 даёт ускорение в ~2.9 раз. Неплохо!
А что, если попробовать float16? Надо же мыслить глобально! А вот там, всё наоборот: ручное перемножение занимает 0.014516, а через even-odd - 0.014259. Фантастика! Итоговое ускорение в ~3.5 раза.
Использование map/unmap вместо копирования данных
Следующая идея заключается в том, чтобы использовать более быстрые буферы (в случае с железками TexasInstruments - это MSMC), к которым OpenCL может дать доступ напрямую. В случае с явным копированием (функция clEnqueueWriteBuffer) данные будут копироваться из пользовательского процесса в буферы устройства. Если же использовать функции clEnqueueMapBuffer и clEnqueueUnmapMemObject, то необходимые для обработки данные можно создавать напрямую в памяти GPU. По идее, это должно сэкономить одно копирование данных.
Вместо:
memcpy(filter->working_buffer + filter->history_offset, input, sizeof(float complex) * input_len);
ret = clEnqueueWriteBuffer(filter->command_queue, filter->input_obj, CL_TRUE, 0, working_len * sizeof(float complex), filter->working_buffer, 0, NULL, NULL);
Можно сразу делать:
filter->working_buffer = clEnqueueMapBuffer(filter->command_queue, filter->input_obj, CL_TRUE, CL_MAP_WRITE, 0, filter->working_len_total, 0, NULL, NULL, &ret);
memcpy(filter->working_buffer + filter->history_offset, input, sizeof(float complex) * input_len);
ret = clEnqueueUnmapMemObject(filter->command_queue, filter->input_obj, filter->working_buffer, 0, NULL, NULL);
Экономится одно копирование памяти. Результат выполнения теста: 0.014397. Почти не отличается. А что же насчёт других типов памяти, которые поддерживает VC4CL? mailbox - это память по-умолчанию, VC4CL_MEMORY_CMA не работает:
Message from syslogd@rasp-buster at Nov 6 23:22:25 ...
kernel:[ 655.225825] bde0: b1f8be04 b1f8bdf0 7f13db60 7f13d9cc b46130c0 00000000 b1f8be1c b1f8be08
А при VC4CL_MEMORY_VCSM просто нельзя выделить нужное количество памяти:
clCreateBuffer: -61
Использование локального буфера
Ещё TexasInstruments советуют попробовать использовать локальные буфера. Работает это так: результат всех вычислений складывать в локальный буфер, а потом его полностью копировать из локальной памяти в глобальную. По их заверениям скорость может увеличиться в 3 раза. Код должен выглядеть следующим образом:
__kernel void fir_filter_process(__global const float *restrict input, __global const float *restrict taps, const unsigned int taps_len, __global float *output, const unsigned int decimation, local float* temp) {
...
int lid = get_local_id(0);
int lsz = get_local_size(0);
...
temp[2 * lid] = real0.s0 + real0.s1 + real0.s2 + real0.s3 + real0.s4 + real0.s5 + real0.s6 + real0.s7;
temp[2 * lid + 1] = imag0.s0 + imag0.s1 + imag0.s2 + imag0.s3 + imag0.s4 + imag0.s5 + imag0.s6 + imag0.s7;
event_t ev = async_work_group_copy(&output[get_global_id(0) * 2], temp, lsz * 2, 0);
wait_group_events(1, &ev);
}
В метод передаётся переменная temp, которая инициализирована в локальной памяти. После этого результат записывается в эту переменную, а потом методом async_work_group_copy копируется в глобальную память. В результате получается: 0.014826. То есть скорость выполнения почти не поменялась.
Использование препроцессора
OpenCL поддерживает такую “замечательную” штуку из языка С как препроцессор. В моём случае, можно часть аргументов функции передать через препроцессор во время компиляции программы. Если taps_len достаточно небольшой, то компилятор сможет развернуть цикл и тем самым ускорить выполнение программы. В тесте у меня размер фильтра 2432, так что я не рассчитываю на какое-либо ускорение. После необходимых изменений, код стал выглядеть следующим образом:
#ifndef TAPS_LEN
#define TAPS_LEN 3
#endif
#ifndef DECIMATION
#define DECIMATION 1
#endif
__kernel void fir_filter_process(__global const float *restrict input, __global const float *restrict taps, __global float *output) {
...
}
А компиляция kernel теперь выглядит так:
snprintf(source_str, MAX_SOURCE_SIZE, "-DTAPS_LEN=%d -DDECIMATION=%d", result->taps_len, result->decimation);
ret = clBuildProgram(program, 1, &result->device_id, source_str, NULL, NULL);
После запуска соответствующего теста, время составило: 0.014072. Чуть-чуть быстрее, но несущественно.
На этом я решил остановиться и закодировать алгоритм с помощью volk, чтобы было с чем сравнивать.
CPU
Итак, чтобы сравнивать производительность с CPU, нужно закодировать абсолютно тот же алгоритм. Я не стал повторять весь этот муторный путь с оптимизациями и наивными реализациями, а сразу написал код так, как он работает в sdr-server (ну, почти так).
Тест производительности выглядит абсолютно так же, как и для OpenCL кода. Параметры фильтра, размер входящих данных. Результат запуска: 0.002152. Ну что я могу сказать? В ~6.5 раз быстрее. ARM ядро работает на частоте 1.2Ггц, а GPU - на частоте 400Мгц. В 3 раза медленнее. Но и параллелизм в GPU больше! 12 потоков против одного.
100% CPU во время работы GPU
Во время запуска тестов я обнаружил, что CPU полностью загружен:
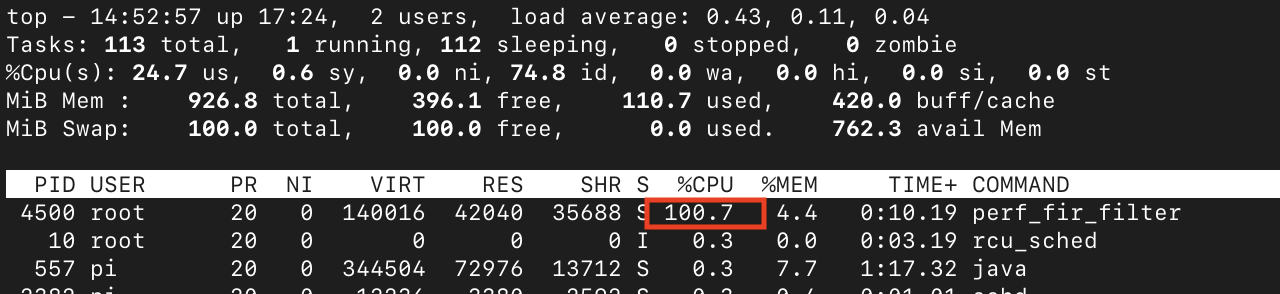
Я бы ожидал, что процессор будет загружен на 20% или 10%, но это не так. Если запустить perf, то можно увидеть следующее:
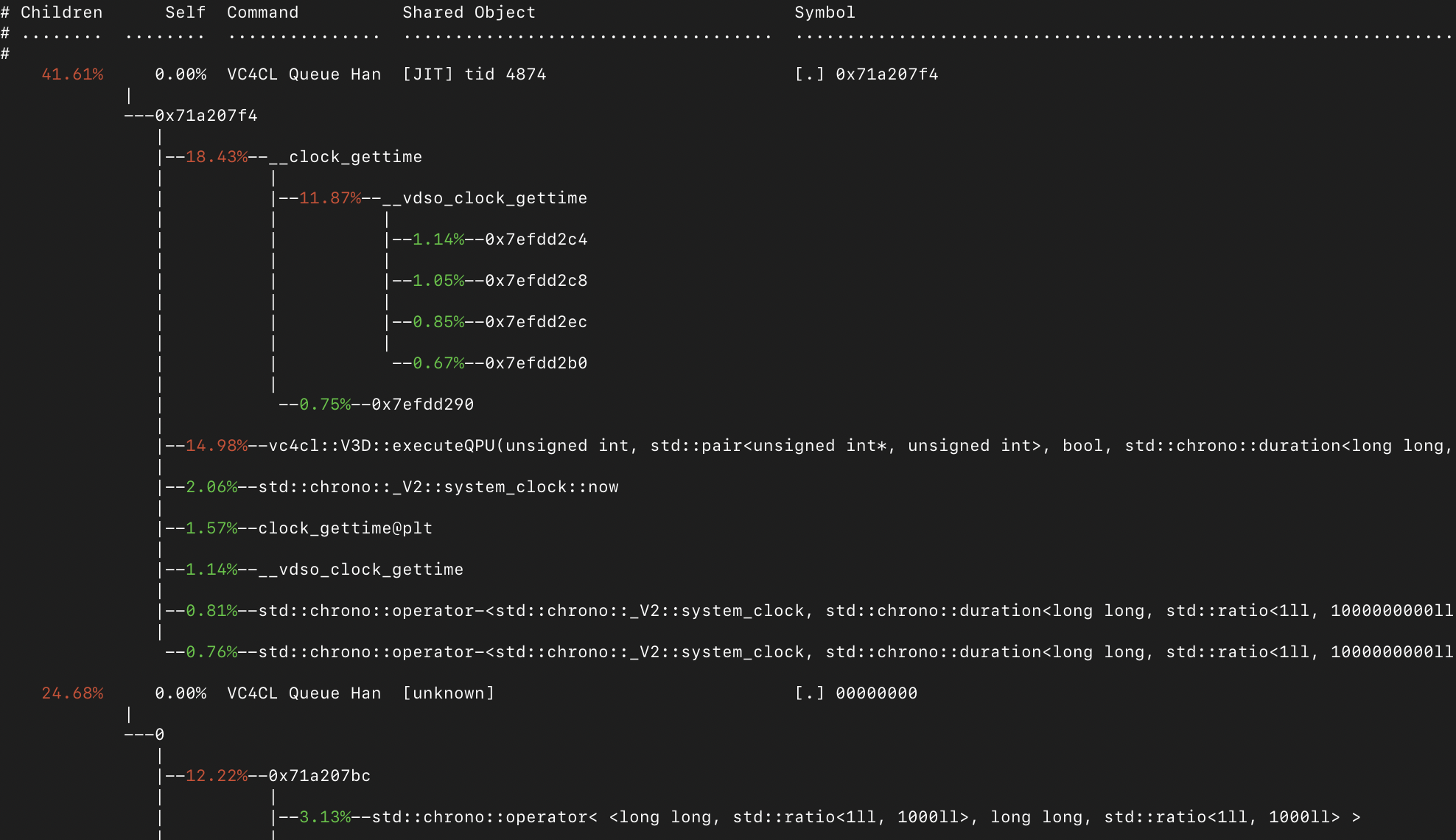
Почти всё время проводится вот в этом участке кода:
while(true)
{
if(((basePointer[V3D_SRQCS] >> 16) & 0xFF) == numQPUs)
return true;
if(std::chrono::duration_cast<std::chrono::milliseconds>(
std::chrono::high_resolution_clock::now() - start) > timeout)
break;
// TODO sleep some time?? so CPU is not fully used for waiting
// e.g. sleep for the theoretical execution time of the kernel (e.g. #instructions / QPU clock) and then
// begin active waiting
}
Если честно, то я не верю, что в чипе нет никакой синхронизации между GPU и CPU. Постоянно проверять результаты и вызывать достаточно дорогую функцию получения времени - не очень хорошая идея.
Выводы
Из хороших новостей: удалось ускорить код в ~3.5 раза. Из плохих новостей: это всё равно в ~6.5 раз медленнее CPU. Ещё из плохих новостей: 100% загрузка CPU сводит на нет всю идею экономии электроэнергии.
Дальше не имеет смысла исследовать, пока не будут решены найденные проблемы. Придётся засучить рукава и попробовать сделать пару pull request. Это же open source!