Ускорение работы FIR фильтра с помощью SIMD NEON
Уже которую неделю я пытаюсь добавить поддержку airspy mini в sdr-server. На этот раз я упёрся в производительность Raspberrypi. При получении сигнала один клиент загружал одно ядро на 80%. Это значит, что sdr-server способен обработать только ~4 параллельных наблюдения. Я скомпилировал и запустил утилиту perf, которая показала интересное - большинство времени тратится внутри драйвера к airspy. На самом деле, там происходит много сложных DSP операций:
static void remove_dc(iqconverter_float_t *cnv, float *samples, int len)
{
int i;
ALIGNED float avg = cnv->avg;
for (i = 0; i < len; i++)
{
samples[i] -= avg;
avg += SCALE * samples[i];
}
cnv->avg = avg;
}
Из-за больших скоростей сэмплирования, процессор должен обрабатывать очень много данных перед тем, как выдать пользователю. Из хороших новостей: если поглядеть в исходные коды, то можно увидеть оптимизации для SSE2. То есть в принципе авторы старались оптимизировать код с помощью интристиков. Из плохих новостей: поддержки ARM нет. Однако, есть одинокий pull request в котором добавлена поддержка NEON и утверждается, что добавление SIMD ускоряет код всего лишь на 4~8%. Мне показалось это странным, так как в одной из моих статей я своими глазами видел ускорение в 2 раза.
ARM-TESTS
Операция свёртки настолько стандартная, что моей первой мыслью было поискать бенчмарки в Интернете. Но я ничего не нашёл! Тогда я вздохнул и решил написать свои. Так и получился проект arm-tests. Идея проекта заключается в том, чтобы проверить выполнение одной и той же операции в разных условиях. Для этого я очень активно использовал директивы препроцессора и cmake. С помощью последнего я смог создать очень много маленьких исполняемых файлов, которые удобно выполнять в любой комбинации и сравнивать результаты.
foreach(TEST_TYPE TEST_GENERIC TEST_NEON4Q TEST_NEON2Q TEST_NEON1Q)
foreach(TEST_MEMORY TEST_ALIGN_MEMORY TEST_NONALIGN_MEMORY)
foreach(TEST_SIZE TEST_ALIGN_SIZE TEST_NONALIGN_SIZE)
foreach(TEST_FETCH TEST_PREFETCH TEST_NOPREFETCH)
set(TEST_ARGUMENTS -D${TEST_TYPE} -D${TEST_MEMORY} -D${TEST_SIZE} -D${TEST_FETCH})
add_executable(dot_prod_${EXEC_SUFFIX} dot_prod.c)
target_compile_options(dot_prod_${EXEC_SUFFIX} PUBLIC ${TEST_ARGUMENTS} -mfpu=neon)
...
endforeach()
endforeach()
endforeach()
endforeach()
Результаты
Я выделил несколько основных факторов, которые могут повлиять на производительность. Самый важный: наличие интристиков. Этот параметр контролирует переменная TEST_TYPE:
- TEST_GENERIC - обычный код на С. Это некоторый базовый уровень от которого будут идти все оптимизации.
- TEST_NEON4Q - загрузка float32 из памяти в регистры сразу по 16 элементов.
- TEST_NEON2Q - загрузка float32 из памяти в регистры сразу по 8 элементов.
- TEST_NEON1Q - загрузка float32 из памяти в регистры сразу по 4 элемента.
Под каждый тип я написал отдельную реализацию свёртки. Идея такого разделения заключается в том, что данные из памяти могут загружаться долго, и поэтому интересно найти такую комбинацию блоков при которой простой процессора минимален.
Я начал со сравнения двух ARM процессоров между собой: BCM2837B0 и Apple M1.

Цель такого сравнения была, конечно же, не в том, чтобы убедиться насколько M1 мощный. А скорее увидеть тренд. И он тут есть: оказывается в независимости от реализации процессора, обработка данных по одному 128-битному регистру быстрее, чем по двум и четырём регистрам.
График выше логарифмический для того, чтобы удобно было видеть тренд. Но если приглядеться к цифрам, то видно, что реализация TEST_NEON1Q в среднем в 2 раза быстрее кода на Си с опциями компиляции -O3 -mfloat-abi=hard -march=armv8-a -mfpu=neon.
Следующим тестом я решил проверить насколько будет влиять выравнивание памяти на результат. Этот параметр контролирует переменная TEST_MEMORY. Для выделения такой памяти я использовал posix_memalign:
#if defined(TEST_ALIGN_MEMORY)
memory_code = posix_memalign((void **)&output, 32, sizeof(float) * output_len);
if( memory_code != 0 ) {
return EXIT_FAILURE;
}
#else
output = malloc(sizeof(float) * output_len);
#endif
Помимо, собственно, создания выравненного массива данных, при обработке нужно указать процессору, что данные выровнены. Делается это с помощью функции __builtin_assume_aligned:
const float *aPtr = (float *) __builtin_assume_aligned(input, MEMORY_ALIGNMENT);
const float *bPtr = (float *) __builtin_assume_aligned(taps, MEMORY_ALIGNMENT);
Если что-то не будет выровнено, то не беда - процессор это сообщит и программа упадёт с ошибкой Bus error.
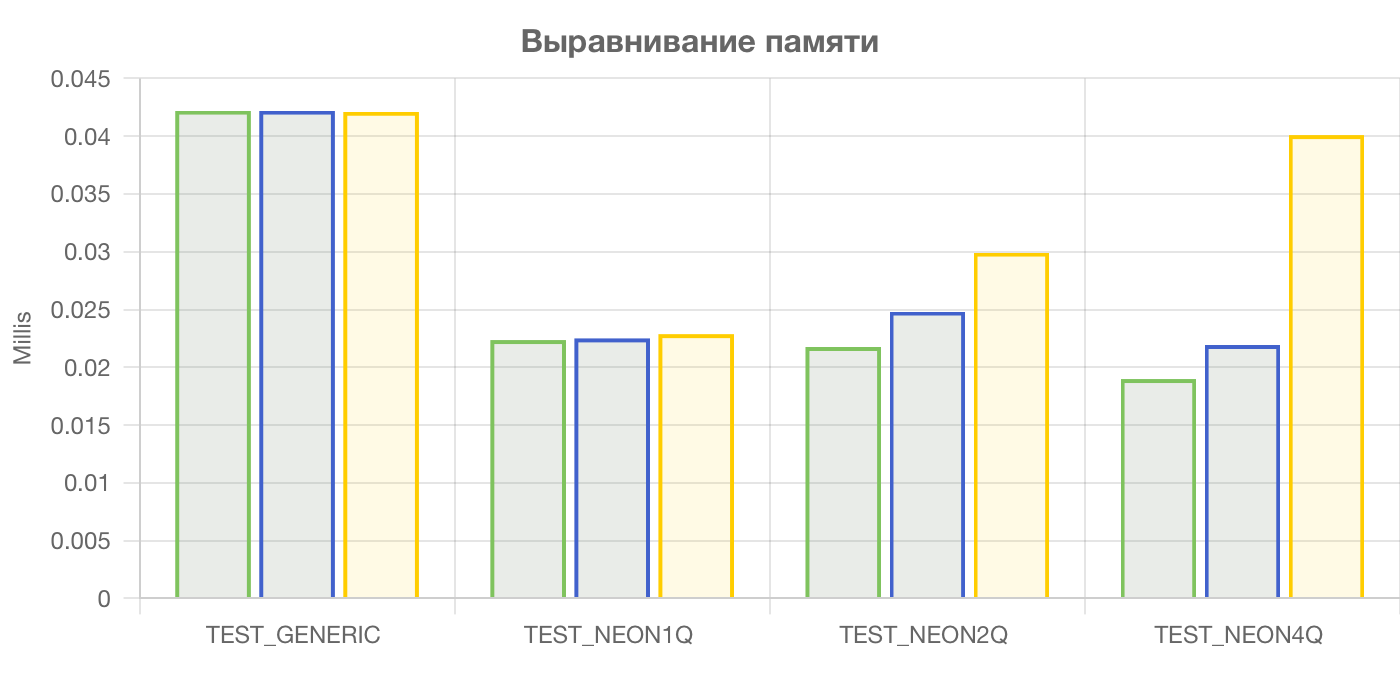
Похоже, выравнивание влияет на производительность только при одномоментной загрузке больших объёмов данных из памяти.
Ещё одним важным фактором может быть длина массивов. Допустим, я загружаю из памяти в регистры по 16 float и параллельно считаю свёртку. Но если длина массива не кратна 16-ти, то остаток можно считать загрузкой 8 или 4 float, либо реализовать на Си. В общем же случае входящий массив может быть не кратен ни 16, ни 8, ни 4, тогда придётся по-любому обсчитывать остаток с помощью кода на Си. А что, если расширить исходные массивы до длины кратной 16, 8 или 4? Процессор будет перемножать нули, складывать с нулями и на результат это не повлияет. При этом остаток будет выполняться такими же быстрыми SIMD инструкциями и код в общем случае будет значительно проще. Выглядеть это может вот так:
#if defined(TEST_NEON2Q) && defined(TEST_ALIGN_SIZE)
if( input_length % 8 != 0 ) {
final_input_length = ((input_length / 8) + 1) * 8;
}
if( taps_length % 8 != 0 ) {
final_taps_length = ((taps_length / 8) + 1) * 8;
final_taps = malloc(sizeof(float) * final_taps_length);
memset(final_taps, 0, sizeof(float) * final_taps_length);
memcpy(final_taps, taps, sizeof(float) * taps_length);
}
Может не очень элегантно, но выполняется один раз и работает как часы.
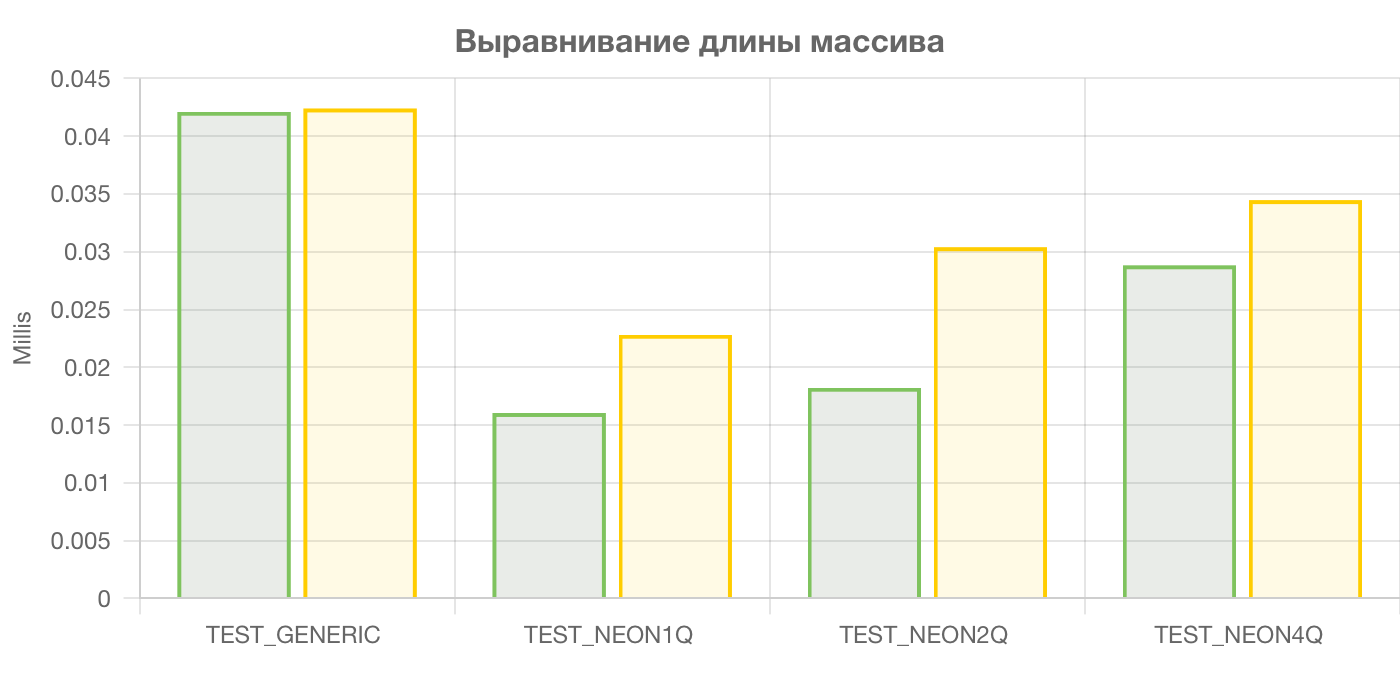
О! Эта оптимизация сработала. На графиках чётко видно ускорение кода для всех функций, написанных с помощью SIMD NEON.
Следующей идеей для оптимизации может быть prefetch данных из памяти. На самом деле это достаточно спекулятивная команда, которая говорит процессору, что скоро будет чтение из заданной области памяти. Я никогда не понимал таких подсказок процессору. Как будто он - человек и такой: “Ну ладно, уговорил. Будет быстрее”. Но почему бы и не попробовать? Тут, правда, не очень понятно в какой момент вызывать эту функцию. Я сделал сразу же после загрузки из памяти:
a_val = vld2q_f32(aPtr);
b_val = vld2q_f32(bPtr);
#if defined(TEST_PREFETCH)
__builtin_prefetch(aPtr+8);
__builtin_prefetch(bPtr+8);
#endif
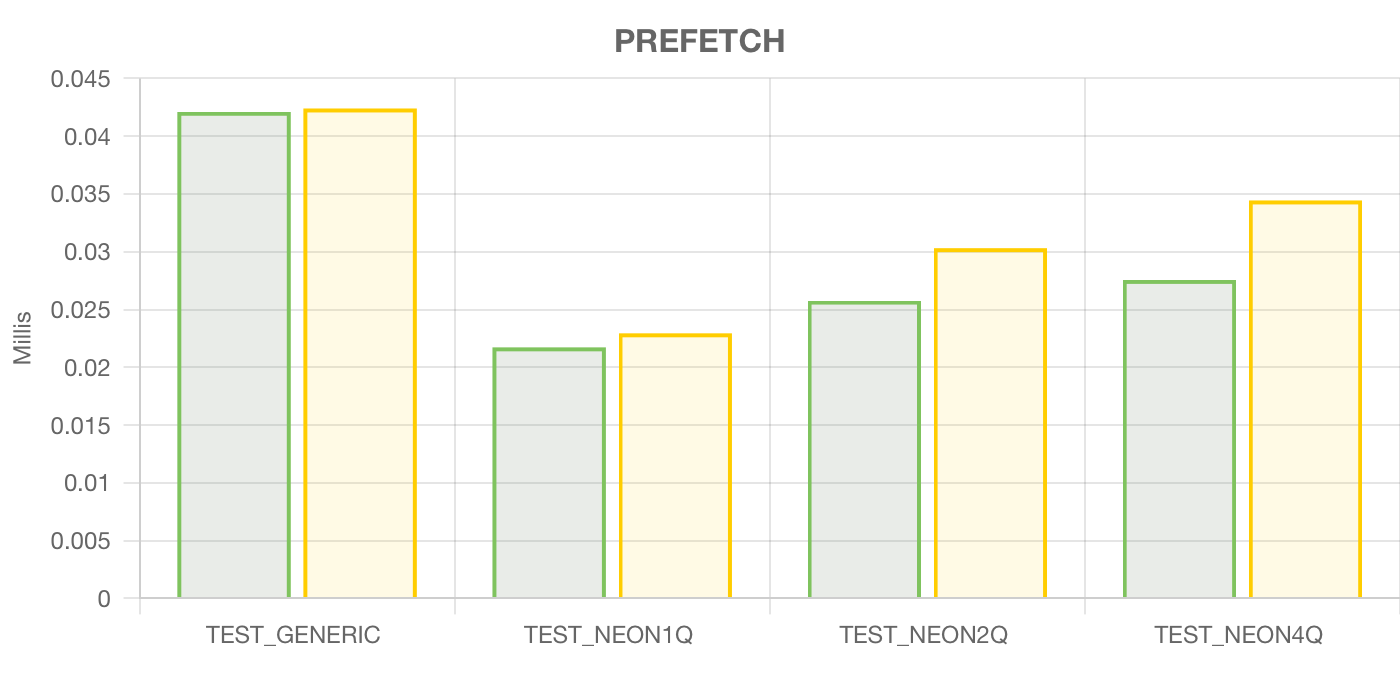
Ну такое. Разница видна, но в рамках погрешности.
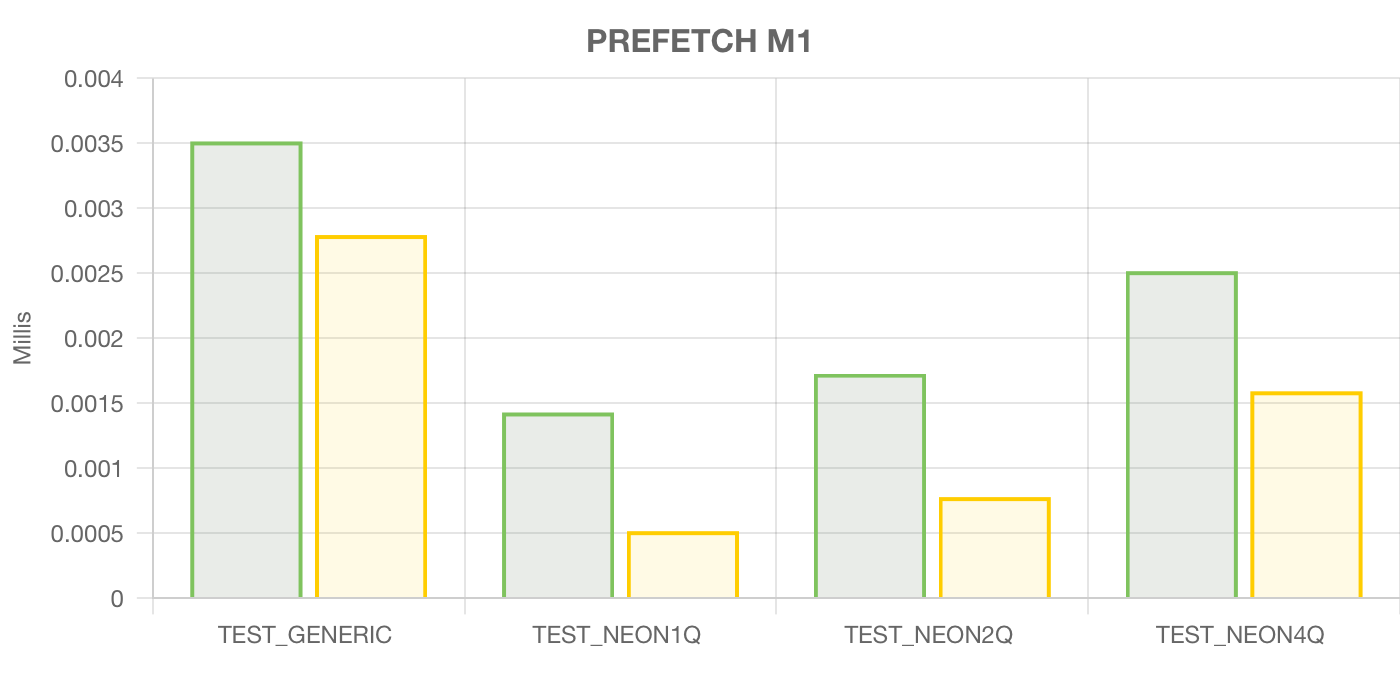
Кстати, на M1 эта оптимизация сделала всё только хуже:
Помимо всех этих оптимизаций я пытался собирать бинарники с разными опциями компиляции:
- без флагов оптимизации компиляции. Только
-mfpu=neon - оптимизация под 64-битные процессоры:
-O3 -mfloat-abi=hard -march=armv8-a -mfpu=neon - оптимизации под 32-битные процессоры:
-O3 -mfloat-abi=hard -march=armv7-a -mfpu=neon
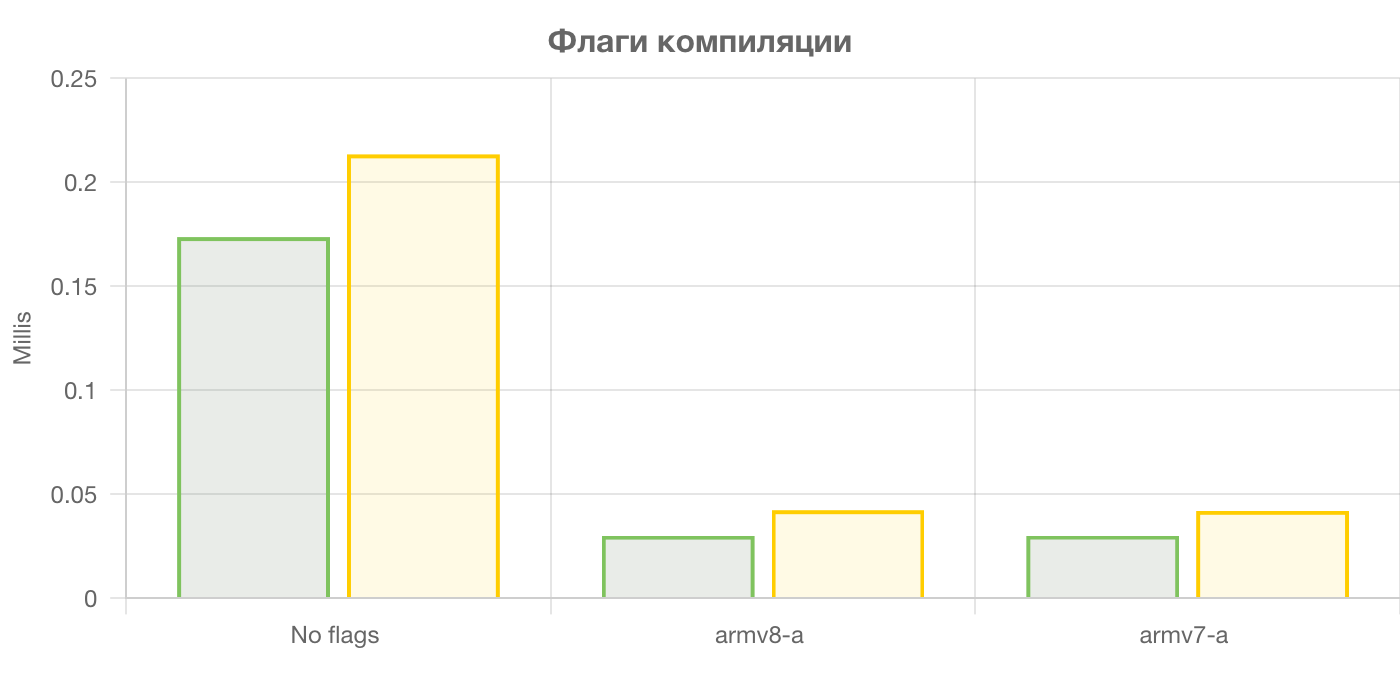
Из графика видно, что компилятор действительно делает что-то полезное и дополнительные флаги ускоряют работу программы. Но при этом реализация алгоритма с помощью интристиков всё равно быстрее.
А ещё видно, что 32-битные и 64-битные инструкции выполняются одинаковое количество времени. Я бы ожидал, что шина 64-битного процессора в 2 раза больше и может загружать в 2 раза быстрее данные из памяти, но такого не происходит.
Выводы
Я ещё немного поиграюсь с разными настройками, но уже ясно, что arm-tests очень удобен для быстрой проверки гипотез. Можно добавить другие алгоритмы и посравнивать.
Кстати, в pull request есть ошибка: используется один и тут же аккумулятор для обработки двух независимых FMA операций. Если использовать два аккумулятора и потом их дополнительно сложить вне цикла, то скорость ожидаемо возрастёт в 2 раза.