Ускорение работы FIR фильтра с помощью SIMD NEON - Часть 2
Несмотря на то, что в моей предыдущей статье я улучшил производительность FIR фильтра в несколько раз, мне показалось это недостаточным. Я проанализировал несколько статей, заметок и различных подходов, найденных в Интернет и попробовал добавить для каждой идеи тест в arm-tests.
Флаги компиляции
Первое, что мне бросилось в глаза - это дополнительные флаги оптимизации для компилятора. Сразу несколько статей упоминают флаги -ftree-vectorize -ffast-math -funroll-loops. Я не стал делать отдельный тест, а просто обновил TEST_GENERIC.
Двойной цикл
Эту идею я нашёл в дипломной работе Performance Optimization of Signal Processing Algorithms for SIMD Architectures, которая показывается чуть ли не первым результатом при поиске в Гугле по запросу “оптимизация DSP SIMD”. Идея заключается в том, что загрузка регистров из памяти и обработка результатов делается в двух независимых циклах. Код начинает загружать следующий блок данных из памяти в регистры, в то время как начинается вычисление предыдущего блока. Из-за того, что операции загрузки данных и вычисления значений независимы, процессор может их выполнять параллельно. Алгоритм выглядит следующим образом:
Loop1
if BufferSize == 0
goto endloop
StartLoop:
Loop2
Store O1 and O2
BufferSize = BufferSize - 16
Loop1
Store O3 and O4
if BufferSize == 0
goto endloop
goto StartLoop
endloop:
Store O1 and O2
Store O3 and O4
Я реализовал этот алгоритм для float32x4_t - TEST_NEON1QI и для float32x4x2_t - TEST_NEON2QI.
Утверждается, что этот алгоритм в 2.635 быстрее авто-векторизированного кода.
Кстати, дипломная работа содержит кладезь различных идей для измерения производительности в целом, а так же оптимизации более сложных DSP алгоритмов. Читается на одном дыхании, так что кайне рекомендую.
Симметричный фильтр
Следующую идею я нашёл в коде драйвера к airspy. Из-за того, что многие FIR фильтры симметричны относительно центра, то можно воспользоваться этим и уменьшить количество операций умножения. Например, применение фильтра с пятью коэффициентами:
result[i] = A*X1 + B*X2 + C*X3 + D*X2 + E*X1
можно преобразовать в:
result[i] = (A + E)*X1 + (B + D)*X2 + C*X3
Это позволит сократить количество умножений в ~2 раза. Правда, не очень понятно будет ли экономия на умножении больше, чем прыжки по памяти туда-сюда. Чтобы это проверить, я реализовал несколько тестов:
- TEST_GENSYMM - наивная реализация. Выполнять алгоритм выше в цикле
(int)(n/2)раз - TEST_NEON1QSYMM - то же самое, но с помощью интристиков.
- TEST_GENCACHE - та же идея, но вручную развёрнутый цикл.
Volk
А зачем самому что-то придумывать, если уже кто-то это реализовал? Именно в этом и заключается идея использовать готовый код из библиотеки volk. В TEST_VOLK я просто вызывал функцию volk_32f_x2_dot_prod_32f с нужными параметрами.
Результаты
Для сравнения я добавил победителя предыдущего раунда оптимизации - TEST_NEON1Q:
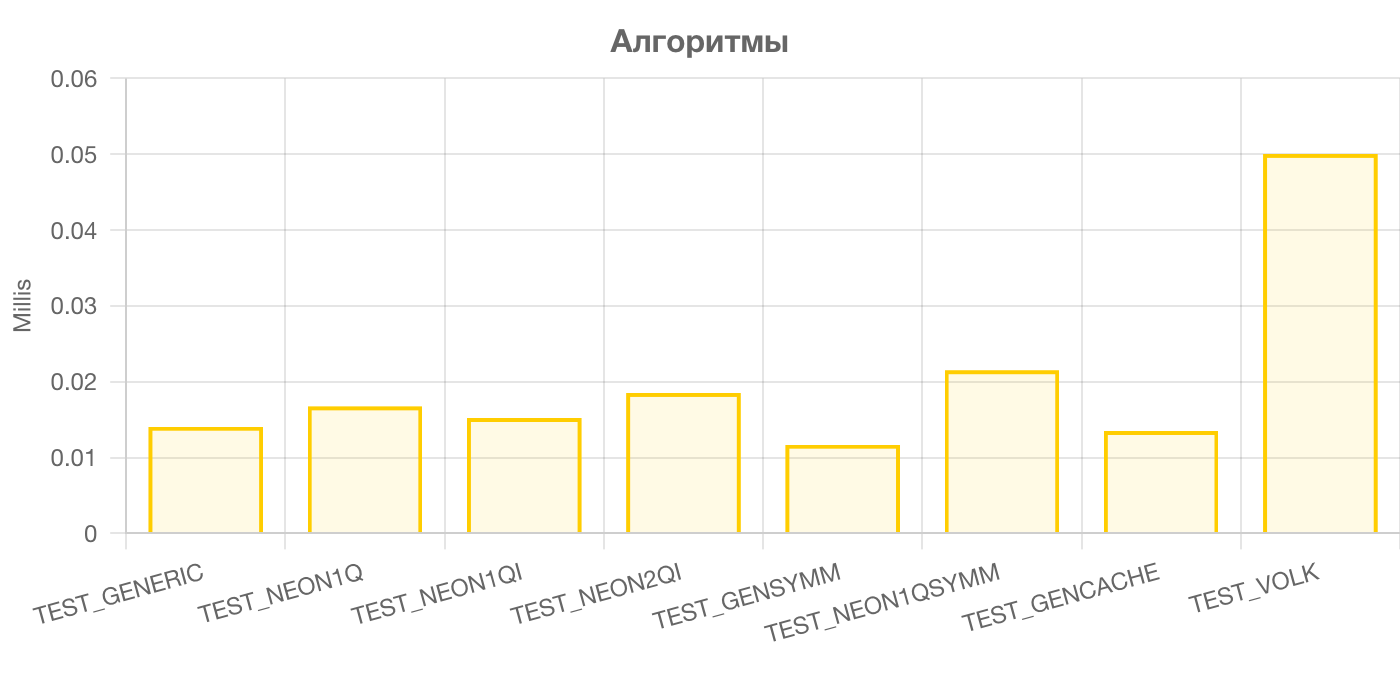
Результаты меня сильно удивили. Во-первых, обычная реализация на Си оказалась быстрее на 17% вручную оптимизированного кода на интристиках. Видимо, разворачивание циклов действительно творит чудеса. Во-вторых, использование симметрии фильтра ещё быстрее. Видимо весь массив попадает в быстрый кэш и прыжки вперёд-назад не влияют на производительность. Это даёт 31% прироста производительсноти по сравнению с TEST_NEON1Q. В-третьих, крайне медленная реализация в библиотеке VOLK. Я несколько раз проверил конфигурацию, и там действительно стоит использование NEON:
$ cat ~/.volk/volk_config
#this file is generated by volk_profile.
#the function name is followed by the preferred architecture.
volk_32f_x2_dot_prod_32f a_neonasm neon
Я попробовал реализации с разным выравниванием памяти, но это не помогло:
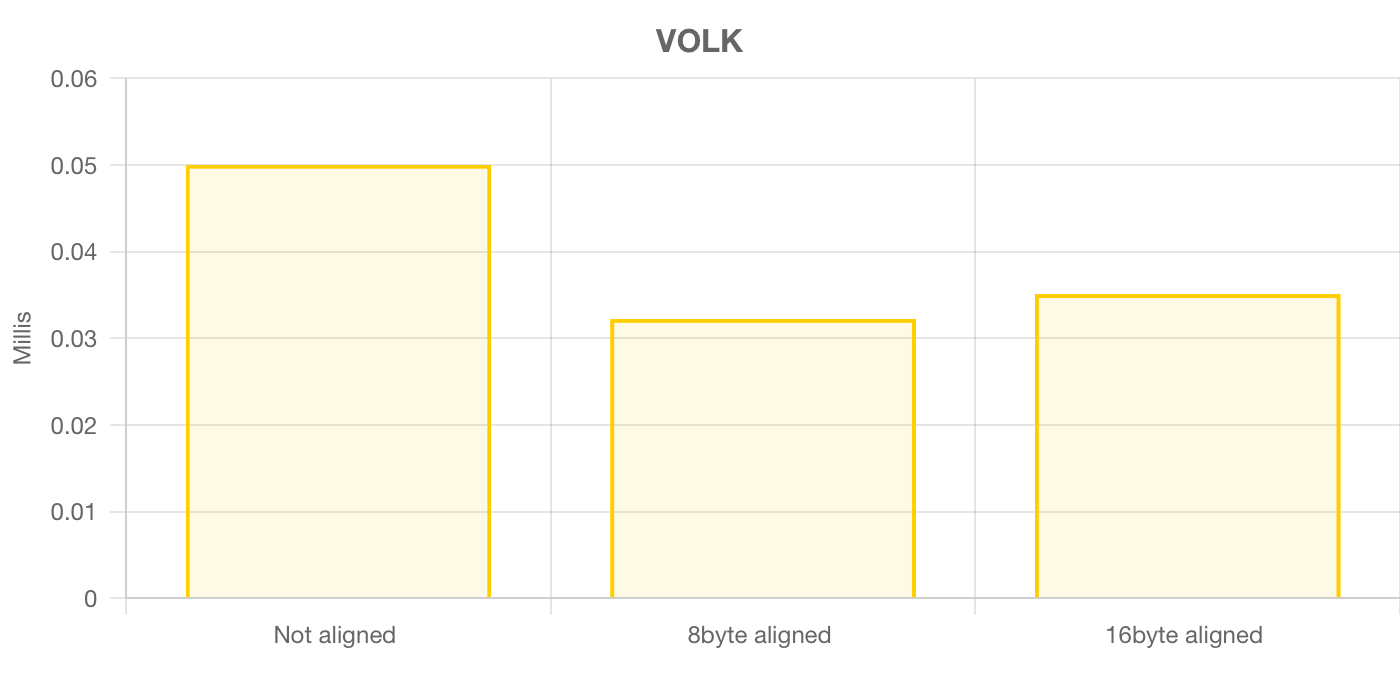
Вероятно, парни намудрили что-то с выбором нужной реализации и компиляцией. Если выбрать generic реализацию, то она значительно быстрее, чем neon, но даже близко не подходит к TEST_GENERIC, несмотря на то, что код абсолютно одинаковый.
Выводы
А выводы всё те же, что и для любой другой оптимизации кода:
- алгоритм должен быть оптимизирован в первую очередь
- если это не помогло, то попробовать разные опции компилятора
- если и это не помогло, то написать код с помощью интристиков
- если и этого не хватило, то попробовать написать на ассемблере
Проблема в том, что оптимизация кода на ассемблере - это NP-полная задача. Для того, чтобы её решить, нужна хорошая интуиция. А чтобы получить такую интуицию, нужно очень много времени заниматься исключительно оптимизацией кода. А вот времени как раз обычно и не хватает.
Бонус
А чем же закончилась история с оптимизацией драйвера к airspy? А там используется half-band фильтр. Его особенность заключается в том, что почти половина его коэффициентов равна 0. Это позволяет сократить количество операций сложения и умножения почти в 2 раза. Только посмотрите насколько он быстрее TEST_GENSYMM:
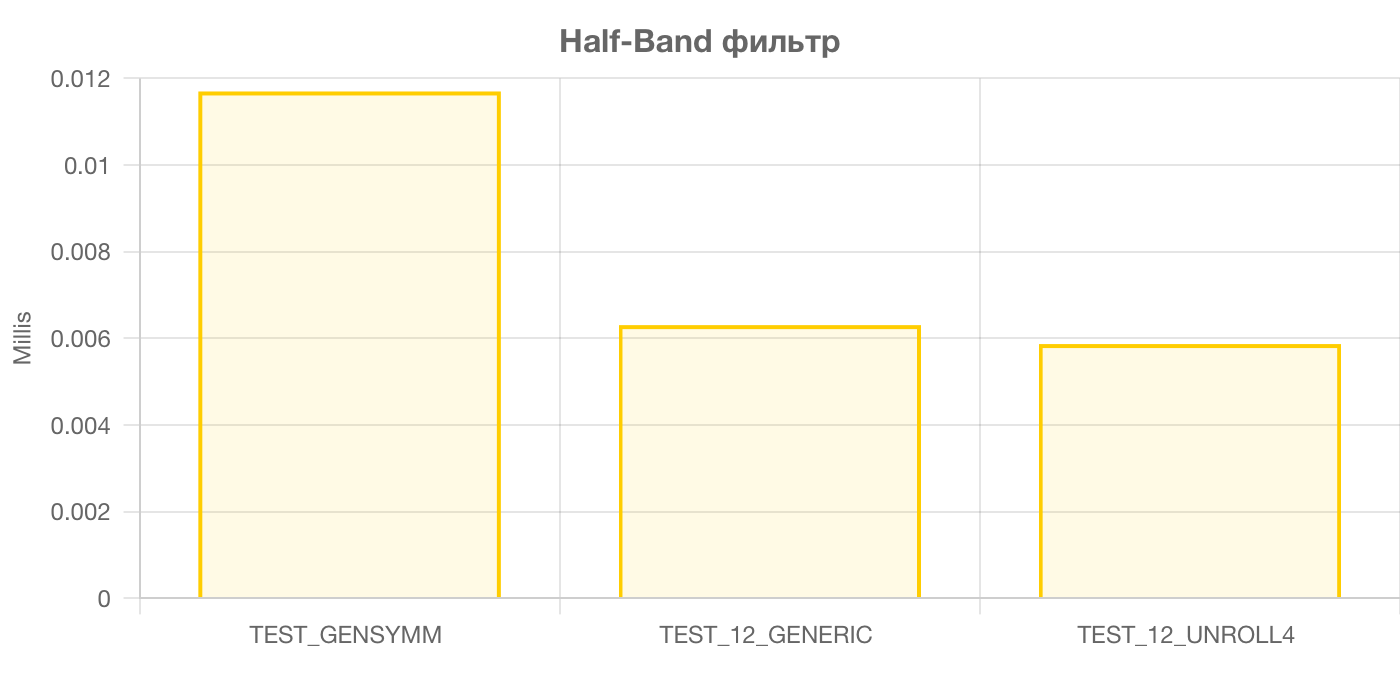
А если вручную развернуть несколько циклов, то скорость увеличится на 41%!
Бонус 2
Фильтр - это не единственная операция, которая выполняется в драйвере airspy! Внутри происходит несколько операций:
- удаление DC смещения из сигнала
- преобразование Гильберта
- децимация сигнала в 2 раза
В коде драйвера каждая операция выполняется в отдельном методе с дополнительными накладными расходами. Например, в кольцевом буфере данные копируются из начала в конец через каждые 47*32 сэмпла:
if (--fir_index < 0)
{
fir_index = fir_len * (SIZE_FACTOR - 1);
memcpy(fir_queue + fir_index + 1, fir_queue, (fir_len - 1) * sizeof(float));
}
Мне непонятен выбор буфера именно такой длины. Что мешало сделать его такой же длины, что и буфера, получаемые из USB?
Ещё одним местом для оптимизации может быть кольцевой буфер с задержкой. В нём есть логический переход, который можно оптимизировать, если использовать массив такой же длины, что и входящий. Для этого нужно заменить код:
for (i = 0; i < len; i += 2)
{
res = cnv->delay_line[index];
cnv->delay_line[index] = samples[i];
samples[i] = res;
if (++index >= half_len)
{
index = 0;
}
}
На:
samples[i+1] = cnv->delay_line[i + 1];
cnv->fir_queue[i + 46 + 1] -= avg;
avg += SCALE * cnv->fir_queue[i + 46 + 1];
cnv->delay_line[i + 1 + 24] = -(cnv->fir_queue[i + 46 + 1] * hbc);
...
samples[i + 3] = cnv->delay_line[i + 3];
cnv->fir_queue[i + 46 + 3] -= avg;
avg += SCALE * cnv->fir_queue[i + 46 + 3];
cnv->delay_line[i + 3 + 24] = cnv->fir_queue[i + 46 + 3] * hbc;
Идея заключается в том, чтобы считать элемент и помещать в промежуточный массив по нужному смещению. При этом текущий брать из промежуточного с текущим смещением.
В результате этих оптимизаций, код стал ещё менее читаемым, зато чуть более быстрым:
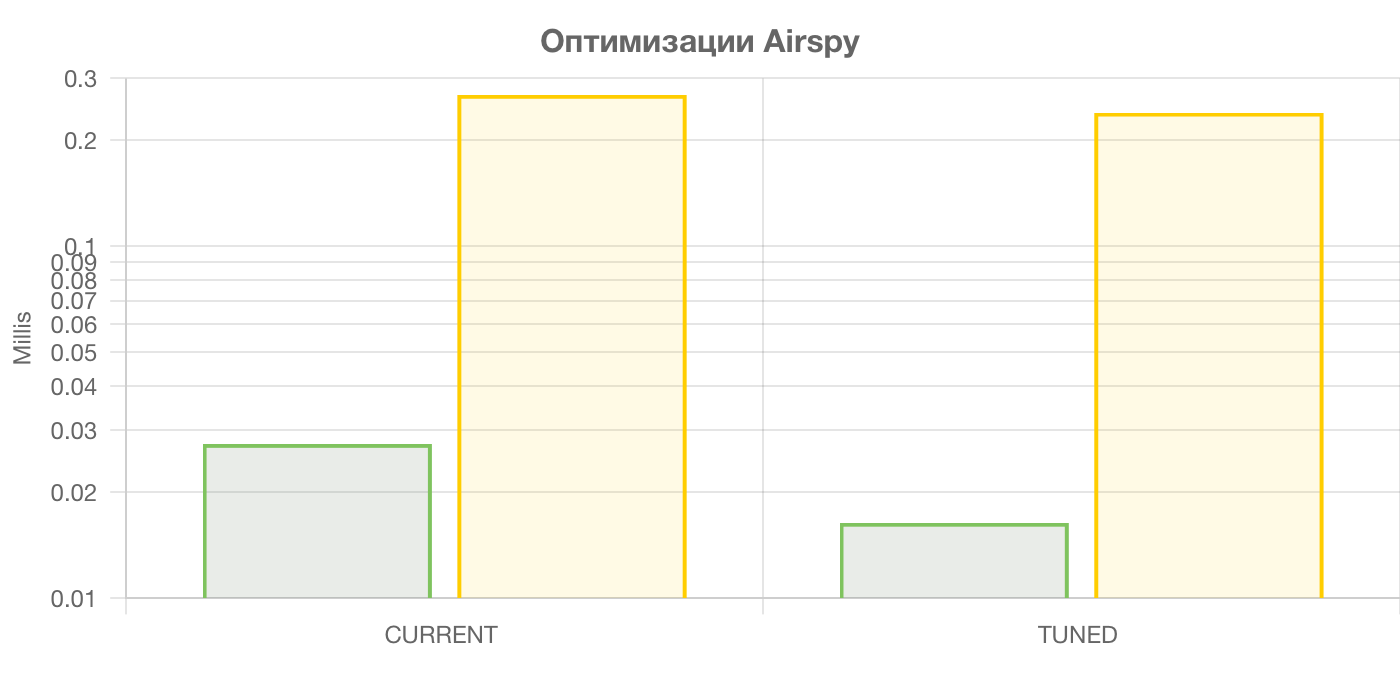
На графике видно, что производительность увеличилась. Для Apple M1 на 41%, а для RaspberryPI на 11%. Цифры не очень впечатляющие. Это всё из-за алгоритма удаления DC смещения. В нём каждый последующий элемент зависит от предыдущего. Таким образом распараллелить вычисление с помощью SIMD не получится.