Установка OpenCL на RaspberryPI
В предыдущей статье я описал основные причины, почему OpenCL вообще нужен, как выглядит типичная программа и какие классы задач стоит считать на GPU. В этой же статье я постараюсь описать установку и настройку OpenCL для RaspberryPI.
VC4CL
Проект VC4CL реализует OpenCL 1.2 API для Raspberrypi. Так как OpenCL компилирует kernel во время инициализации основной (host) программы, то нам понадобится компилятор!
Компилятор называется VC4C. Этот компилятор основан на LLVM. Он компилирует kernel в промежуточное представление SPIR-V, которое уже стандартными средствами LLVM проверяется и переводится в ассемблерный код для конкретного GPU.
Именно поэтому первым делом нужно поставить LLVM и парочку необходимых зависимостей:
sudo apt-get install llvm-9 opencl-headers ocl-icd-dev ocl-icd-opencl-dev clinfo
Далее, необходимо установить специальный транслятор, который будет переводить SPIR-V во внутренне представление LLVM. Здесь важно ставить версию, такую же как и LLVM. Например, для LLVM 9 нужно использовать ветку llvm_release_90:
git clone --depth=1 --branch llvm_release_90 https://github.com/KhronosGroup/SPIRV-LLVM-Translator.git
mkdir SPIRV-LLVM-Translator/build
cd SPIRV-LLVM-Translator/build
cmake ..
make
sudo make install
После этого собрать VC4C компилятор:
git clone https://github.com/doe300/VC4C.git
mkdir VC4C/build
cd VC4C/build
cmake ..
make
sudo make install
Далее нужно собрать стандартную библиотеку. OpenCL предоставляет некоторые встроенные методы и функции, которые чем-то похожи на стандартную библиотеку. Соответственно, чтобы VC4C смог слинковать их с kernel, нужно собрать стандартную библиотеку. Она достаточно небольшая:
git clone https://github.com/doe300/VC4CLStdLib.git
mkdir VC4CLStdLib/build
cd VC4CLStdLib/build
cmake ..
make
sudo make install
После этого, можно собрать VC4CL:
git clone https://github.com/doe300/VC4CL.git
mkdir VC4CL/build
cd VC4CL/build
cmake ..
make
sudo make install
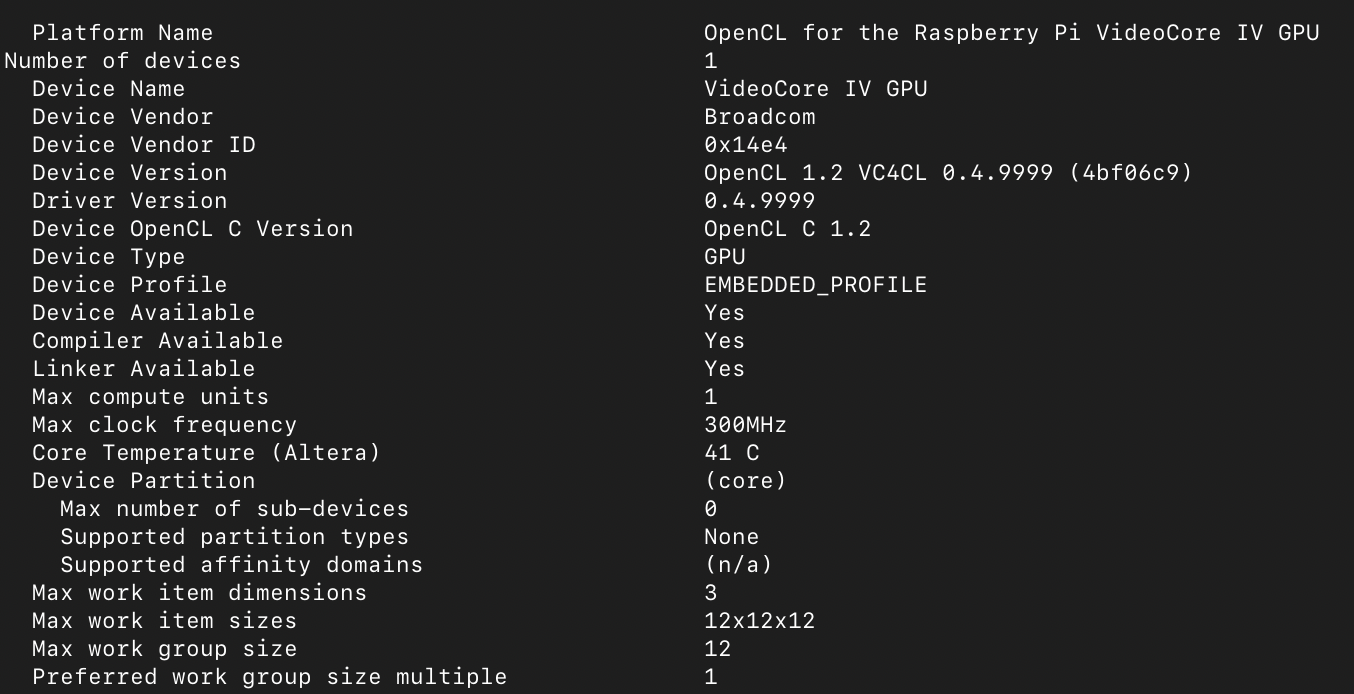
После того как установлены необходимые компоненты, можно проверить результат. Команда sudo clinfo должна выдать хотя бы одно доступное устройство:
clDsp-test
Я создал небольшой проект на github - clDsp-test. В нём я реализовал КИХ-фильтр, который является наиболее узким местом Frequency Xlating FIR filter. С помощью него я могу сравнить производительность CPU и GPU. Этот тест выбран неслучайно. Именно этот фильтр находится в центре sdr-server и является наиболее узким местом системы.
Поддержка OpenCL подключается в проект следующим образом:
pkg_check_modules(PC_OpenCL REQUIRED OpenCL)
include_directories(${PC_OpenCL_INCLUDE_DIRS})
target_link_libraries(clDsp ${PC_OpenCL_LINK_LIBRARIES})
Инициализация OpenCL происходит следующим образом:
- Сначала подключается заголовок:
#define CL_TARGET_OPENCL_VERSION 120
#include <CL/cl.h>
- Потом происходит поиск устройства и инициализация:
cl_int ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms);
ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_ALL, 1, &device_id, &ret_num_devices);
context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);
command_queue = clCreateCommandQueue(context, device_id, 0, &ret);
API OpenCL позволяет находить доступные устройства в рантайме и запускать код одновременно на нескольких устройствах.
- Создание буферов обмена между хостом и GPU:
input_obj = clCreateBuffer(context, CL_MEM_READ_ONLY, working_len_total * sizeof(float complex), NULL, &ret);
taps_obj = clCreateBuffer(result->context, CL_MEM_READ_ONLY, taps_len * sizeof(float complex), NULL, &ret);
output_obj = clCreateBuffer(result->context, CL_MEM_WRITE_ONLY, result->output_len * sizeof(float complex), NULL, &ret);
- Компиляция загруженной программы:
program = clCreateProgramWithSource(result->context, 1, (const char **) &source_str, (const size_t *) &source_size, &ret);
clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);
- Создание объекта kernel и задание аргументов:
kernel = clCreateKernel(program, "fir_filter_process", &ret);
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *) &input_obj);
...
clSetKernelArg(kernel, 4, sizeof(cl_uint), &decimation);
Код самого ядра (kernel) выглядит следующим образом:
__kernel void fir_filter_process(__global const float *restrict input, __global const float *restrict taps, const unsigned int taps_len, __global float *output, const unsigned int decimation, const unsigned int output_len) {
for (unsigned int i = 0; i < output_len; i++) {
int output_offset = (get_global_id(0) * output_len + i) * 2;
int input_offset = output_offset * decimation;
float real0 = 0.0f;
float imag0 = 0.0f;
for (unsigned int j = 0; j < taps_len; j++) {
real0 += (input[input_offset + 2 * j] * taps[2 * j]) - (input[input_offset + 2 * j + 1] * taps[2 * j + 1]);
imag0 += (input[input_offset + 2 * j] * taps[2 * j + 1]) + (input[input_offset + 2 * j + 1] * taps[2 * j]);
}
output[output_offset] = real0;
output[output_offset + 1] = imag0;
}
}
После того как OpenCL проинициализирован, код ядра загружен и скомпилирован, всё готово к обработке данных. В главном цикле программы или обработчика необходимо:
- Записать входные данные в буфер CPU/GPU:
clEnqueueWriteBuffer(command_queue, input_obj, CL_TRUE, 0, working_len * sizeof(float complex), working_buffer, 0, NULL, NULL);
- Вызвать обработку данных:
clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL, &work_items, &local_item_size, 0, NULL, NULL);
- Прочитать результат:
clEnqueueReadBuffer(command_queue, output_obj, CL_TRUE, 0, result_len * sizeof(float complex), filter->output, 0, NULL, NULL);
Вот, собственно, и всё. В массиве filter->output будет находиться результат.
Тонкости
А дальше начинаются тонкости. Например, как устроено копирование памяти? В главном цикле программы, данные находятся в оперативной памяти. Но для того, чтобы GPU смог их обработать, их нужно скопировать в GPU память. OpenCL API позволяет это сделать двумя способами:
- просто скопировав из одного буфера данных в другой с помощью функции
clEnqueueWriteBuffer. - с помощью функции
clEnqueueMapBuffer, которая возвращает указатель на адрес памяти в которую нужно записать данные. И функцииclEnqueueUnmapMemObject, когда нужно вернуть указатель назад в библиотеку.
Такой API достаточно гибок - он позволяет копировать память как в SoC системах, так и через PCI express шину на отдельно выделенную видеокарту. При этом каждый разработчик OpenCL сам решает, как именно будет реализовано копирование. Например, в VC4CL есть целых 3 способа копирования данных! Все эти способы можно переключать с помощью переменной среды:
- VC4CL_MEMORY_MAILBOX - используется по-умолчанию. Это специальный способ коммуникации между CPU & GPU в Raspberrypi. Он основан на стандартом mailbox API, который предоставляется ядром Linux.
- VC4CL_MEMORY_VCSM. VCSM - специальный драйвер для работы с GPU памятью в Raspberrypi.
- VC4CL_MEMORY_CMA - вторая версия VCSM драйвера. Наверное, лучше было бы назвать переменную VC4CL_MEMORY_VCSM_CMA. Новая версия драйвера поддерживает CMA (Contiguous Memory Allocator). Видимо, из-за того, что память выделяется большими последовательными участками, она лучше ложится в DMA и быстрее обрабатывается/копируется.
При этом запустить код VC4CL может тремя другими способами:
- VC4CL_EXECUTE_REGISTER_POKING - используется по-умолчанию. Запись команд и чтение результатов напрямую из драйвера V3D или VC4. С этими драйверами всё очень запутанно. V3D - это новый драйвер, который поддерживает новую версию OpenGL ES на Raspberrypi 4. VC4 - это старый драйвер для Raspberrypi 1,2,3. При этом в системе может быть загружено два драйвера одновременно и они не совместимы. Наверное, это сделано для того, чтобы обеспечить совместимость операционной системы и разных версий Raspberrypi. И да, переменную надо было бы назвать VC4CL_EXECUTE_V3D.
- VC4CL_EXECUTE_MAILBOX. Всё тот же интерфейс mailbox, через который можно запускать код.
- VC4CL_EXECUTE_VCHI - более низкоуровневый драйвер для коммуникации ARM ядра и GPU. Чем-то похож на VCSM, только используется для запуска программ.
Зачем нужно знать все эти тонкости реализации OpenCL? Да потому, что не все они работают. Также разные драйвера работают на разных уровнях абстракций. Например, mailbox доступен клиентским приложениям, но из-за того, что он задействует ядро, то обработка, в теории, будет чуть медленнее. Напротив, работа с более низкоуровневыми драйверами требует sudo и нестабильна (а может просто неправильно реализована).
В своих тестах я запускал программу с помощью sudo, потому что это наиболее протестированный и рабочий способ, согласно автору VC4CL.
Далее
В следующей статье я постараюсь описать замеры производительности и возможные способы ускорения OpenCL приложений на примере моего несчастного фильтра. И, конечно же, будет сравнение с CPU. Иначе зачем всё это?