Синхронизация кадров в Метеор-М №2
Введение
Спутник Метеор-М №2 передаёт информацию согласно протоколу LRPT. Этот протокол определяет физический, канальный и сетевой уровни модели OSI. На физическом уровне используется QPSK модуляция. На канальном уровне LRPT подразумевает использование кадров фиксированного размера с интерливингом и несколькими методами коррекции ошибок. Однако, на практике Метеор-М №2 не использует часть алгоритмов из стандарта. В этой статье я хотел бы описать как необходимо синхронизировать и получать кадры Метеор-М №2.
Генерация кадров
Прежде, чем делать получение кадров, необходимо понять как они создаются на спутнике. Алгоритм частично описан в стандарте LRPT и частично в интернете. Итак, первым шагом данные, которые необходимо отправить, разбиваются на кадры фиксированной длины. После этого, к каждому кадру добавляется синхро-маркер 1ACFFC1D

После этого данные кодируются свёрточным алгоритмом со скоростью 1/2. Из этого следуют две важные вещи:
- количество выходных данных увеличивается вдвое
- синхро-маркер становится другим. Это очень важно понимать для правильной синхронизации кадров, о которой я напишу чуть позже

И… На этом всё. Несмотря на то, что стандарт предписывает ещё дополнительные преобразования данных (спойлер: Метеор-М №2-2 их всё-таки реализует), Метеор-М №2 получившийся поток данных сразу отправляет QPSK модулятору.
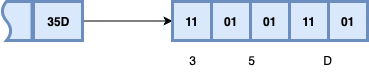
Синхронизация кадров
В общем виде, для того, чтобы синхронизировать кадры, необходимо найти синхро-маркер и прочитать фиксированное количество байт кадра. На практике же, такой подход будет находить крайне малое количество кадров. Прежде всего из-за помех в принимаемом сигнале. Поэтому все алгоритмы по синхронизации кадров сильно отличаются от алгоритмов генерации кадров.
Забегая вперёд скажу, что для декодирования свёрточного кода применяется алгоритм Витерби. При этом алгоритм работающий с мягкими решениями демодулятора в среднем на 2дб эффективнее, чем с жёсткими решениями. Это значит, что каждый входящий бит будет передаваться в виде байта.

В самом простом виде, алгоритм синхронизации имеет некий регистр жёстких решений демодулятора, который он постоянно сравнивает с искомым синхро-маркером 035D49C24FF2686B. Каждый последующий байт конвертируется в бит и добавляется в регистр.
byte bitToCheck;
if (inputByte > 0) {
bitToCheck = 1;
} else {
bitToCheck = 0;
}
dataRegister = (dataRegister << 1) | (bitToCheck & 0x1);
Если регистр совпал с необходимым синхро-маркером, то из потока читается кадр фиксированного размера и декодируется с помощью алгоритма Витерби.
Этот алгоритм можно улучшить. Дело в том, что в синхро-маркере 035D49C24FF2686B могут быть ошибочные биты. Алгоритм Витерби может скорректировать ошибочные биты как в самом синхро-маркере, так и в данных, идущих за ним. Зная это, можно искать синхромаркер с некоторой точностью. Например, для Метеор-М №2 на основе экспериментов я допускаю до 17 ошибочных бит в регистре или 26%. Тут важно понимать, что небольшой порог не позволит находить пакеты в шумном сигнале, а слишком большой порог даст много ложно-положительных срабатываний.
Чтобы сделать ещё одно улучшение, надо понимать устройство QPSK демодулятора. Любой некогерентный PSK демодулятор подвержен так называемой ошибке неоднозначности фазы.
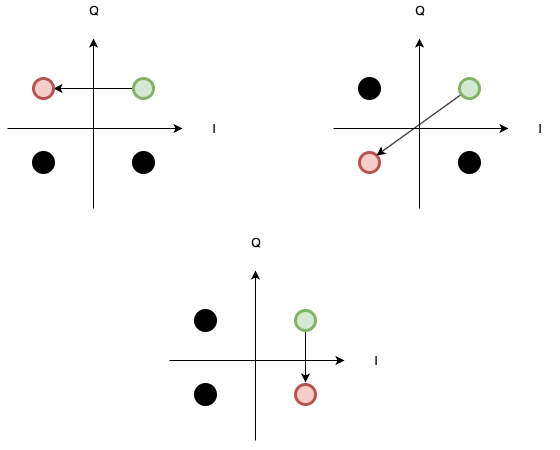
Для алгоритма это значит, что нужно искать не 035D49C24FF2686B, а 8 различных вариантов синхро-маркера. Для этого я создал класс PhaseAmbiguityResolver, который на вход принимает значение синхро-маркера, а на выходе выдаёт все возможные синхро-маркеры в зависимости от ошибки фазы.
Далее алгоритм меняется следующим образом. В потоке бит ищется 8 различных вариантов синхро-маркера. Как только синхро-маркер найден, читается кадр фиксированного размера. Далее, в зависимости от найденного синхро-маркера, каждые 2 бита данных вращаются по часовой стрелке или против. Это необходимо для того, чтобы устранить ошибку неоднозначности фазы в самом кадре.
Выводы
Несмотря на то, что алгоритмы формирования кадров достаточно простые, алгоритмы поиска уже значительно сложнее. Зачастую они ставят перед выбором: количество успешно найденных кадров или увеличенное время (CPU/память) на поиск. Текущий алгоритм синхронизации кадров даёт вполне неплохие результаты.